
Il file robots.txt è uno strumento importante nell’Ottimizzazione per i Motori di Ricerca che viene spesso sottovalutato. Se usato correttamente aiuta a guidare i motori di ricerca in modo mirato attraverso un sito web, mentre, se configurato in modo errato, può costare traffico prezioso.
- Cos'è il robots.txt?
- Struttura e sintassi del robots.txt
- A cosa serve (e a cosa non serve) il robots.txt?
- Utilità
- Istruzioni inutili o non necessarie
- SEO: a cosa prestare attenzione
- Errori comuni
- Best Practices
- Testare il robots.txt con SISTRIX
- Modello per un robots.txt ottimizzato per i motori di ricerca
- Come verificare un robots.txt
- 1. Google Search Console: "robots.txt Tester"
- 2. Test Locale nel Browser
- Robots.txt e Crawler AI
- È possibile proteggere i contenuti dallo scraping da parte degli strumenti AI tramite robots.txt?
- Importante da sapere
- Alcuni consigli
- Cosa dice OpenAI riguardo al robots.txt?
- Esempio di robots.txt per il controllo dei Crawler di OpenAI:
- FAQ sul robots.txt
Breve panoramica: controllare efficacemente i Crawler tramite robots.txt
Il file robots.txt controlla quali parti di un sito possono essere scansionate dai motori di ricerca. Esso si trova nella directory principale (ad esempio, www.iltuo-dominio.it/robots.txt) e aiuta a utilizzare in modo sensato il Crawl Budget (budget di scansione).
Struttura Tipica:
Un file robots.txt è composto da istruzioni per specifici crawler:
User-agent: * Disallow: /admin/ Allow: /admin/login/ Sitemap: https://www.iltuo-dominio.it/sitemap.xml
User-agent: per quale Crawler vale la regola (“*” = tutti).
Disallow: aree che non devono essere scansionate.
Allow: eccezioni all’interno di aree bloccate.
Sitemap: indicazione per i motori di ricerca per una più rapida indicizzazione.
Compiti: escludere aree tecniche, evitare scansioni non necessarie, includere la Sitemap.
Evitare Errori Tipici: non bloccare contenuti importanti.
Cos’è il robots.txt?
Il robots.txt è un semplice file di testo che si trova nella directory principale di un sito (ad esempio, www.iltuo-dominio.it/robots.txt) e fornisce ai motori di ricerca le cosiddette istruzioni di scansione: ovvero, indicazioni su quali aree del sito possono essere cercate e indicizzate, e quali no.
I motori di ricerca come Google di solito rispettano le istruzioni contenute in questo file, che però non sono vincolanti. Per i contenuti sensibili, è quindi importante utilizzare meccanismi di protezione tecnici aggiuntivi come password o blocchi IP.
Struttura e sintassi del robots.txt
Il file segue una struttura semplice composta da uno User-agent (per quale Crawler vale l’istruzione?) e da un Disallow (cosa non deve essere scansionato?). Ecco un esempio:
User-agent: *
Disallow: /admin/
Disallow: /login/
User-agent: *significa che la regola vale per tutti i Crawler.Disallow: /admin/vieta la scansione della directory/admin/.
Se si aggiunge una riga con Allow:, è possibile consentire specificamente un’eccezione all’interno di un’area bloccata:
User-agent: Googlebot
Disallow: /shop/
Allow: /shop/prodotti/A cosa serve (e a cosa non serve) il robots.txt?
Utilità
- Esclusione di aree tecniche: ad esempio
/wp-admin/,/cgi-bin/ - Protezione da scansioni non necessarie: evitare URL con filtri o Duplicate Content
- Indicazione sulla Sitemap:
Sitemap: https://www.iltuo-dominio.it/sitemap.xml
Istruzioni inutili o non necessarie
- Esclusione di contenuti importanti: pagine di prodotti o articoli di blog non dovrebbero essere esclusi.
- Nascondere dati sensibili: i dati sensibili non dovrebbero essere accessibili pubblicamente in primo luogo, poiché il robots.txt non è uno strumento di sicurezza.
- Uso come controllo dell’indicizzazione: vietare la scansione non significa automaticamente che i contenuti non vengano indicizzati (a questo scopo è destinato il Meta-Robots Tag).
SEO: a cosa prestare attenzione
Errori comuni
- Blocco completo del sito con
Disallow: /(spesso dimenticato sui siti di staging) - Blocco di risorse (ad esempio CSS o JS) di cui Google ha bisogno per il rendering
- Mancanza d’indicazione della Sitemap: rende l’indicizzazione più difficile
Best Practices
- Verificare e adattare regolarmente il robots.txt
- Testare con Google Search Console: lì Google indica se i contenuti vengono bloccati per errore
- Utilizzare in modo efficiente il Crawl Budget: escludere le pagine non importanti, mantenere quelle rilevanti liberamente accessibili
Ulteriori Informazioni sulla Creazione del robots.txt.
Testare il robots.txt con SISTRIX
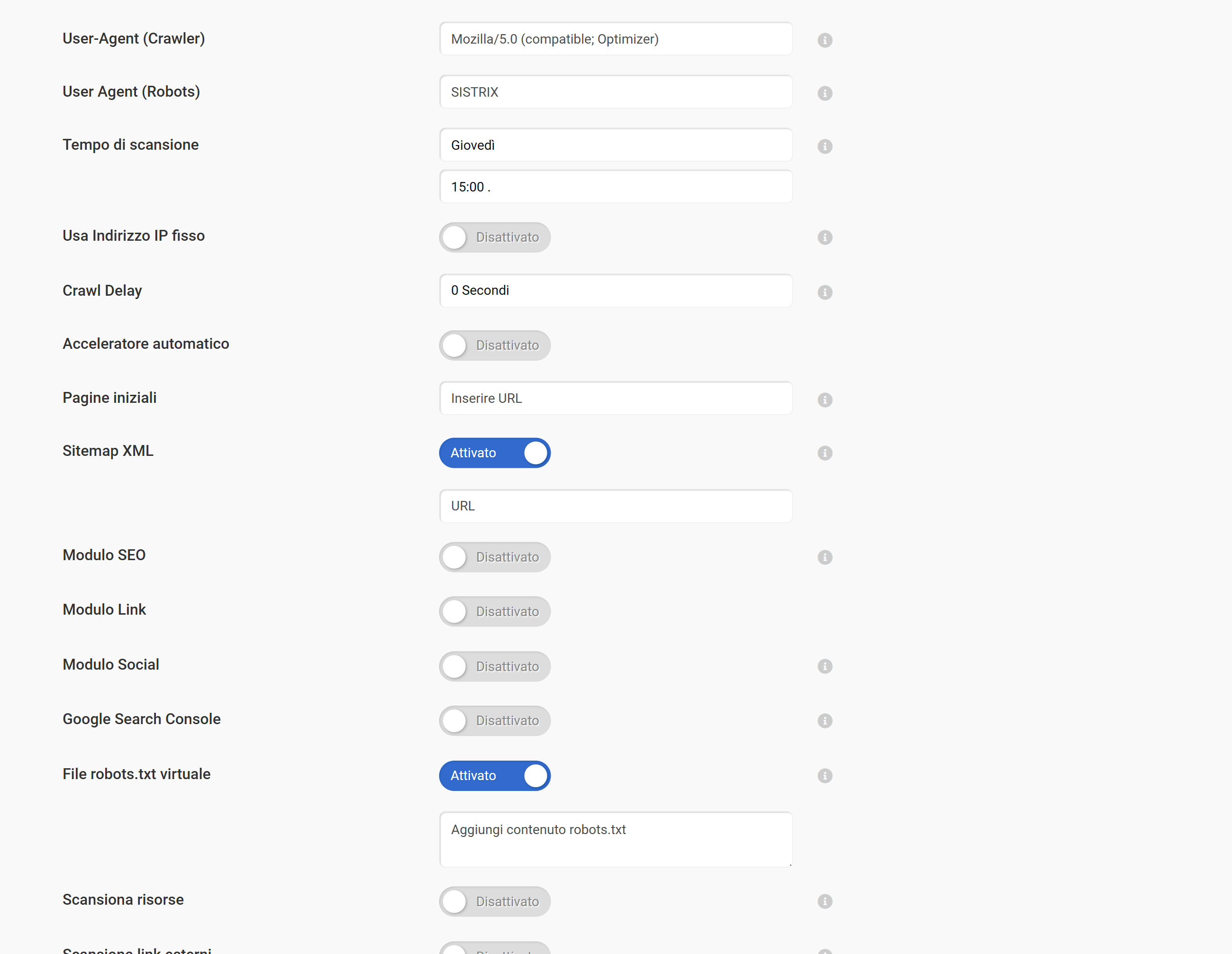
Nei progetti di SISTRIX puoi avviare una scansione per testare il robots.txt del tuo sito: il nostro Crawler lo leggerà e rispetterà le regole in esso contenute, esattamente come avviene con Googlebot.
Le modifiche al robots.txt possono essere testate senza che debbano essere subito pubblicate online. A tale scopo, nelle impostazioni del progetto può essere depositato un robots.txt virtuale, che viene utilizzato esclusivamente per il Crawler interno e sostituisce la versione accessibile al pubblico alla scansione successiva. In questo modo, le nuove regole possono essere verificate senza rischi, né impatto sui motori di ricerca reali.
Scopri subito come sfruttare SISTRIX per il tuo business online! Sette giorni per provare l’intero tool senza alcun costo nascosto, né disdetta necessaria: testa subito SISTRIX gratuitamente.
Modello per un robots.txt ottimizzato per i motori di ricerca
L’esempio seguente mostra un file robots.txt che funziona per la maggior parte dei siti (i percorsi devono essere adattati individualmente).
# Accesso consentito per tutti i crawler
User-agent: *
# Escludere directory irrilevanti per gli utenti e per Google
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /cgi-bin/
Disallow: /carrello/
Disallow: /checkout/
Disallow: /account/
# Non bloccare risorse come CSS o JS (Google ne ha bisogno per il rendering)
# Eccezione: se sai che una directory contiene solo dati tecnici, puoi escluderla
# Evitare la scansione di URL di filtro e ordinamento (Esempio per un e-commerce)
Disallow: /*?orderby=
Disallow: /*?filter=
Disallow: /*?add-to-cart=
# Escludere i risultati di ricerca sul sito (spesso Duplicate Content)
Disallow: /?s=
Disallow: /ricerca/
# Specificare la Sitemap – aiuta Google con l'indicizzazione
Sitemap: https://www.iltuo-dominio.it/sitemap.xml
Come verificare un robots.txt
1. Google Search Console: “robots.txt Tester”
Come funziona:
- Accedi a Google Search Console.
- Seleziona la Property corrispondente (il tuo sito).
- Vai su Strumenti e Report Precedenti > robots.txt Tester (nota: Google sta gradualmente eliminando questo strumento, potrebbe essere ancora disponibile a seconda della Property).
- Carica o incolla il tuo file robots.txt attuale o pianificato.
- Verifica i singoli URL: Google indica se sono bloccati o accessibili.
2. Test Locale nel Browser
- Apri www.iltuo-dominio.it/robots.txt.
- Controlla se il file viene caricato correttamente.
- Fai attenzione a una sintassi priva di errori e all’assenza di voci
Disallowindesiderate.
Suggerimento: testa prima di pubblicare
Se non sei sicuro, non pubblicare immediatamente il tuo file robots.txt modificato: utilizza piuttosto le opzioni di test, soprattutto per siti con molto traffico o contenuti sensibili.
Robots.txt e Crawler AI
È possibile proteggere i contenuti dallo scraping da parte degli strumenti AI tramite robots.txt?
Molti strumenti AI, in particolare i grandi modelli linguistici come ChatGPT, Google Gemini o Claude, utilizzano Webcrawler per raccogliere contenuti accessibili pubblicamente. Questi Crawler, come GPTBot (OpenAI), CCBot (Common Crawl) o Google-Extended, affermano di rispettare le istruzioni contenute nel robots.txt.
Istruzioni esemplificative per bloccare questi Crawler:
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Google-Extended
Disallow: /
Importante da sapere
- Solo i Crawler che aderiscono al robots.txt non accederanno ai tuoi contenuti.
- Gli Scraper o i bot illegittimi che non rispettano gli standard semplicemente ignoreranno il file.
Il robots.txt non è quindi una protezione assoluta contro lo Scraping, ma piuttosto un segnale di opt-out come garanzia legale.
Alcuni consigli
- Se non desideri che i tuoi contenuti vengano utilizzati per l’addestramento dei modelli AI, dovresti bloccare attivamente i Crawler rilevanti.
- Inoltre, può essere utile implementare misure di protezione del Server (ad esempio Bot-Management o blocchi IP).
Legalmente, l’argomento rimane controverso: alcune aziende integrano addirittura nei loro Termini di Utilizzo il divieto dell’uso dei loro contenuti da parte dei modelli AI.
Cosa dice OpenAI riguardo al robots.txt?
OpenAI offre ai SEO la possibilità di controllare in modo mirato il modo in cui i loro contenuti possono essere utilizzati dai diversi Crawler di OpenAI. Il controllo avviene sempre tramite il robots.txt, ma OpenAI distingue tra diversi Crawler, a seconda dello scopo.
Ecco una panoramica:
| User Agent | Uso da parte di OpenAI |
|---|---|
| GPTBot | Utilizzato per scansionare contenuti per l'addestramento di modelli di AI generativa (ad esempio ChatGPT). Disallow nel robots.txt segnala che i contenuti non possono essere utilizzati per scopi di training. |
| OAI-SearchBot | Serve per visualizzare siti web nelle funzionalità di ricerca di ChatGPT (ad esempio tramite integrazione con Bing Search). Non viene utilizzato per l'addestramento dell'AI. OpenAI raccomanda di consentire questo crawler se si desidera apparire nei risultati di ricerca di ChatGPT. |
| ChatGPT-User | Viene utilizzato quando un utente visita una pagina web in ChatGPT (ad esempio tramite plugin, Custom GPTs o GPT Actions). Non è un crawler automatico, non utilizza i dati per l'addestramento dell'AI. Questi accessi si basano su azioni specifiche dell'utente. |
Esempio di robots.txt per il controllo dei Crawler di OpenAI:
# Impedisci che i contenuti vengano utilizzati per l'addestramento AI
User-agent: GPTBot
Disallow: /
# Consenti di apparire nei risultati di ricerca di ChatGPT
User-agent: OAI-SearchBot
Allow: /
# Non bloccare le azioni dell'utente tramite ChatGPT-User (opzionale)
User-agent: ChatGPT-User
Allow: /
Fonte: https://platform.openai.com/docs/bots
FAQ sul robots.txt
Come posso visualizzare il file robots.txt?
Basta digitare nel browser www.iltuo-dominio.it/robots.txt.
Il robots.txt è utile per la SEO?
Sì, se aiuta a utilizzare le risorse di scansione in modo efficiente e a escludere contenuti irrilevanti.
Come trovo il robots.txt su WordPress?
Molti hoster lo generano automaticamente. Con plugin come Yoast SEO o Rank Math puoi personalizzarlo.
Come risolvo “Blocked by robots.txt” su WordPress?
Verifica su Search Console quali URL sono interessate. Successivamente, modifica il robots.txt e rimuovi la voce Disallow.
È meglio usare robots.txt o i Meta-Tag?
Per il controllo della scansione : robots.txt. Per l’indicizzazione: Meta Robots Tag (ad esempio noindex).
Cos’è un Generatore di robots.txt?
Uno strumento per la creazione di file robots.txt senza doverli scrivere manualmente, ideale per i principianti.
Google ignora il robots.txt?
No, Google di solito lo rispetta, a meno che non si tratti di contenuti che necessitano di protezione particolare (ad esempio, dati legalmente rilevanti).
Come aggiungo una sitemap.xml nel robots.txt?
Basta aggiungerla alla fine del file: Sitemap: https://www.iltuo-dominio.it/sitemap.xml
Come aggiungo una sitemap.xml e un robots.txt su WordPress?
Con plugin come Yoast SEO o Rank Math puoi configurare comodamente entrambi, inclusa la creazione automatica della Sitemap.
Prova SISTRIX gratis
- Account di prova gratuito per 7 giorni
- Nessun obbligo, né disdetta necessaria
- Onboarding personalizzato con esperti