
Ormai non passa settimana che Google non debba fare i conti con recriminazioni collegate al suo potere di mercato. Dirk Lewandowski, professore all’Università di Scienze Applicate (HAW) di Amburgo, ha ipotizzato l’idea di sostituire Google con un Web Index pubblico. Potrebbe davvero funzionare?
Google sta diventando uno dei fatti di cronaca più citati nella sezione News, più di quanto un motore di ricerca dovrebbe essere. Già solo negli ultimi giorni, ad esempio, la società di gestione collettiva VG Media gli ha richiesto il pagamento di 1,24 miliardi di euro sulla base dei nuovi diritti d’autore. Inoltre, sotto pressione della Commissione UE, esso dovrà comunicare in tempi brevi un’alternativa a Chrome e alla sezione di ricerca su Android, a cui si aggiunge il fresco ricorso di Idealo da 500 milioni di euro.
In questo contesto Dirk Lewandowski, professore di Information Research & Information Retrieval all’Università di Scienze Applicate (HAW) di Amburgo, nonché uno dei “professori di motori di ricerca” in Europa, ha presentato una proposta (qui la versione PDF) in cui tratta di separare un motore di ricerca in singole parti:
A proposal for building an index of the Web that separates the infrastructure part of the search engine – the index – from the services part that will form the basis for myriad search engines and other services utilizing Web data on top of a public infrastructure open to everyone.
https://arxiv.org/abs/1903.03846
Egli sostiene infatti che il problema chiave della configurazione di un algoritmo di ranking sia il fatto che quest’ultimo si basa sempre sull’interpretazione del mondo dello stesso motore di ricerca: questo significa che non è possibile ottenere dei risultati veramente neutrali ed imparziali. Si tratta quindi di un bel problema, contando che in Europa Google possiede il 90% della quota di mercato.
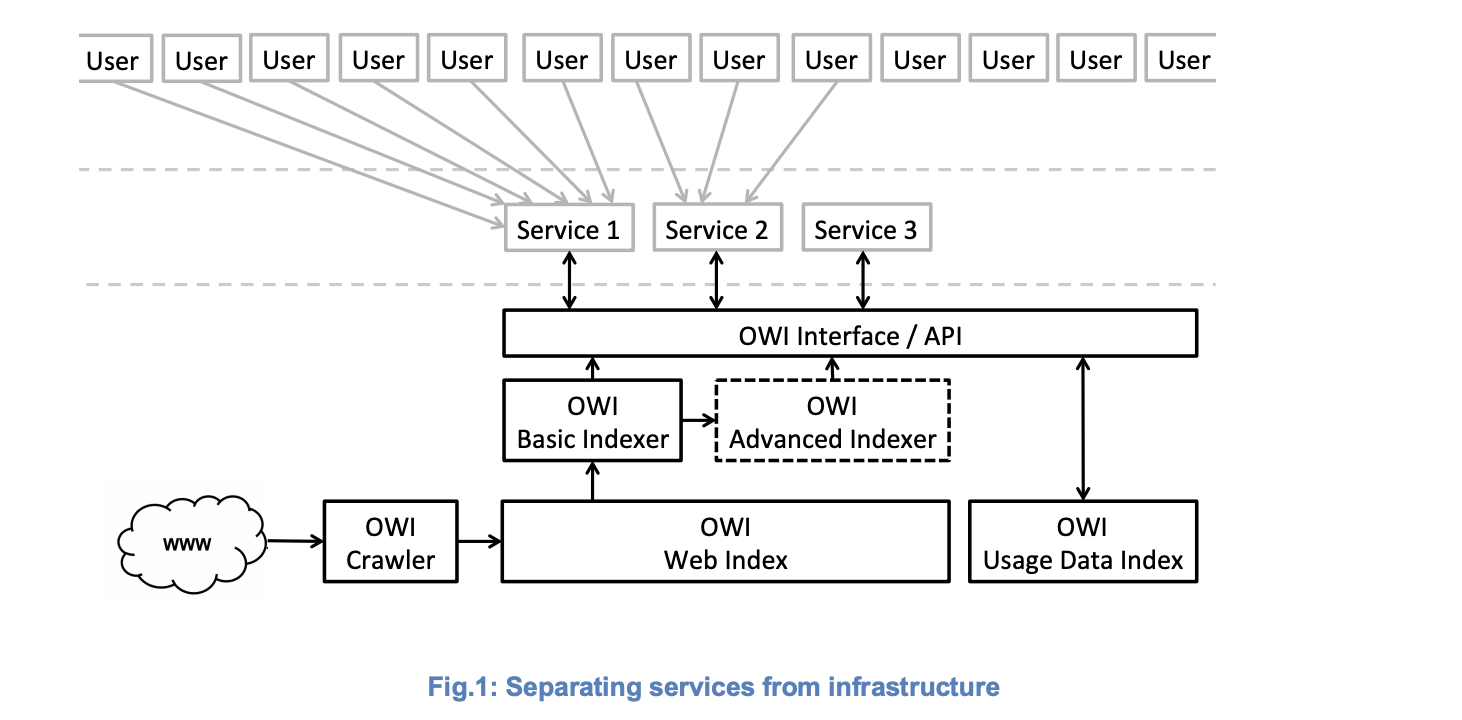
La soluzione, secondo Lewandowski, è la separazione del Crawling/Index e del Frontend/algoritmo dei motori di ricerca. Grazie ad un’infrastruttura pubblica si permetterà lo sviluppo di ulteriori risultati di ricerca, generando una varietà che, ad oggi, è urgentemente necessaria.
Potrebbe davvero funzionare? Ne sono molto scettico, e per due motivi:
A Google appartiene l’intero “Stack”
Al momento Google possiede (nel vero senso della parola) una grande porzione di internet. Non solo: il suo Server DNS, pubblico e gratuito, è quello più utilizzato in assoluto. In più, grazie ad Android, Google possiede lo Smartphone OS di maggior successo, mentre la quota di mercato di Chrome su desktop raggiunge regolarmente picchi massimi. Infine, oltre a Google Analytics, non esistono concorrenti che abbiano un simile livello di mercato. Potrei continuare questa lista all’infinito. E se anche Google non possedesse ancora un pezzo del puzzle che gli serve, non gli basterà che comprarselo (come nel caso dei Search Deals di Apple e Firefox).
La ricerca ai tempi del Machine Learning: la quantità conta
Non mi è ancora ben chiaro se i dati siano ormai il nuovo petrolio o oro (so solo che non li posso più sentir nominare). Una cosa però è inequivocabile: la tesi alla base è giusta. All’epoca del Machine Learning sono sempre di più gli Hardware e i Software pubblici. Sono i Training Data a differenziare la qualità di un risultato dell’algoritmo, e in questo campo Google ha un vantaggio enorme: da una parte, come precedentemente detto, esso ha accesso a molto più di puri e semplici dati di ricerca; dall’altra, il suo volume di ricerca (anche nel settore Long Tail) è ormai talmente grande da permettergli di offrire comunque risultati rilevanti. Quello che propone Lewandowski è un ripristino dei dati degli utenti dei singoli motori di ricerca all’interno del sistema globale. Non sono però così certo che questa soluzione possa compensare gli svantaggi strutturali.
Cambiare non è semplice
Esistono delle alternative a Google, anzi ne esistono tante e, oggettivamente parlando, sono anche molto buone. Eppure sono quelli di Google i risultati che quasi tutti desiderano. La fiducia maturata negli anni nei confronti di questo marchio è talmente elevata che è difficile convincere gli utenti a cambiare: preferiscono ottenere i risultati di Bing con il layout di Google, piuttosto che i risultati di Google con il design di Bing. Perché si possa assistere ad un vero e proprio cambio di motore di ricerca, l’alternativa a Google deve essere veramente migliore.
Riassunto
Qualsiasi input verso una maggiore varietà nel panorama dei motori di ricerca europei è utile e gradito. L’idea di offrire un crawler e un indice come forma di assistenza pubblica in Europa, così da permettere una maggiore concorrenza, è condivisibile sotto un profilo accademico. Rimango tuttavia scettico che possa funzionare nell’internet reale. C’è da dire che l’UE ha già finanziato diversa roba, per cui chissà, tentar non nuoce.
