
Il “Query fan-out” (espansione delle query) nei sistemi di ricerca basati sull’AI è un procedimento in cui una richiesta dell’utente non viene semplicemente elaborata nella sua interezza, bensì automaticamente scomposta in diverse query parziali (“Subqueries”). Ciò avviene solo per le query di ricerca complesse, per le quali è necessario ricercare più aspetti per trovare una risposta.
Google ha brevettato questo principio nel dicembre 2024 e lo descrive come segue.
Cosa dice Google?
Quando un utente seleziona un argomento mostrato, il sistema genera automaticamente una seconda, più specifica, query di ricerca, combinando la query originale con l'argomento scelto, e fornisce quindi al browser nuovi risultati di ricerca che si riferiscono esclusivamente a questo argomento ora circoscritto.
Queste query parziali elaborano in parallelo diverse sfaccettature della domanda originale e, successivamente, i risultati vengono aggregati in una risposta coerente.
Query fan-out nella pratica
Ecco come funziona il Query fan-put nella pratica:
- La query originale, ovvero il prompt, viene analizzata semanticamente e scomposta in diversi sottodomini significativi;
- Ogni subquery viene ricercata in modo indipendente (ad esempio, sul web, nei database, nel Knowledge Graph);
- I risultati vengono ponderati e uniti per fornire una risposta coerente;
- La risposta appare all’utente nel giro di secondi come “unica e uniforme”, nonostante in background siano stati eseguiti diversi percorsi di ricerca paralleli.
La correttezza di una risposta dipende da diversi aspetti, tra cui la qualità del prompt, la fedeltà fattuale dei dati di addestramento o del risultato di ricerca e la ponderazione all’interno del modello linguistico.
Esempio
Supponiamo che un utente chieda: “Qual è il miglior sistema CRM per una startup?”
Con l’approccio classico verrebbe fornita una risposta con un elenco di tre sistemi CRM e una raccomandazione.
Con Query fan‑out, invece, il sistema scompone la richiesta, ad esempio nelle seguenti sotto-domande:
- “Quali sistemi CRM sono economici per le startup?”
- “Quali sistemi CRM offrono molte integrazioni e API?”
- “Quali sistemi CRM sono conformi alla protezione dei dati nell’UE (GDPR)?”
- “Quali sono le recensioni delle startup sulla scelta del CRM?”
Il sistema ricerca in parallelo queste sotto-domande, attinge a dati e fonti, pondera i risultati e produce una risposta più complessa con diverse opzioni, ognuna con il contesto del perché è adatta a specifici tipi di startup.
Se quindi sei un Provider di CRM e vuoi apparire in queste risposte, questo significa concretamente che non puoi limitarti semplicemente a presentare solo il tuo CRM, bensì dovresti copri anche tutte le sotto-domande rilevanti (prezzo, API, risultati dei test, GDPR, target,…) e utilizzare titoli, tabelle e sezioni FAQ per rispondere chiaramente ad esse.
Rilevanza pratica per la SEO
Perché il Query fan-out è rilevante per la SEO? Perché, grazie ad esso, la logica delle query di ricerca e l’utilizzo dei contenuti da parte dei sistemi di ricerca cambiano notevolmente.
Impatto in sintesi
1. Intento dell’utente multidimensionale
- Una query contiene spesso diverse domande implicite parziali: un sistema con logica Fan-out le riconosce automaticamente e fornisce risposte a tutti questi aspetti. Per i contenuti, questo significa che non è più sufficiente rispondere in modo pulito a una singola domanda, bensì bisogna considerare quali sotto-domande potrebbero derivare dalla domanda principale (ad esempio, aspetti tecnici, alternative, possibilità di utilizzo, costi, rischi).
2. La profondità contenutistica e l’ampiezza semantica acquistano importanza
- I contenuti che coprono diverse sfaccettature di un argomento vengono preferenzialmente inclusi dai sistemi di ricerca AI. Le pagine con un focus isolato su una piccola domanda sono in svantaggio nella competizione rispetto a quelle con un’illuminazione tematica più ampia.
4. Struttura e leggibilità per le macchine
- Siccome un sistema AI elabora più subquery in parallelo, i contenuti devono essere strutturati in modo da essere facilmente estraibili: titoli chiari, sezioni a struttura modulare, tabelle o blocchi FAQ per coprire le sotto-domande. Senza tale struttura, un motore di ricerca AI difficilmente può integrare un contenuto come modulo di risposta.
5. Visibilità tramite citazioni al posto dei classici ranking
- Nell’ambito di sistemi come Google Gemini o l'”AI Mode” di Google, non è più rilevante il mero raggiungimento nei ranking organici, bensì la domanda: la mia pagina viene inclusa come risposta (Citation)? I contenuti che appaiono come modulo di risposta in un sistema generativo guadagnano visibilità, anche se il traffico e i click diminuiscono.
Scoprire i Prompt con SISTRIX
Fin qui tutto bene, ma quali prompt citano effettivamente il mio brand o la mia entità, eventualmente senza che la domanda di partenza li contenga?
Per adattare i contenuti a un Query fan-out è utile analizzare esattamente i prompt e le domande in cui il proprio brand compare, così da riconoscere le correlazioni tematiche per pianificare contenuti appropriati e strutture chiare.
Non solo: lo stesso procedimento può essere seguito per analizzare i siti concorrenti, identificando, riassumendo e presidiando strategicamente prompt e query di ricerca classiche nei moderni sistemi di ricerca.
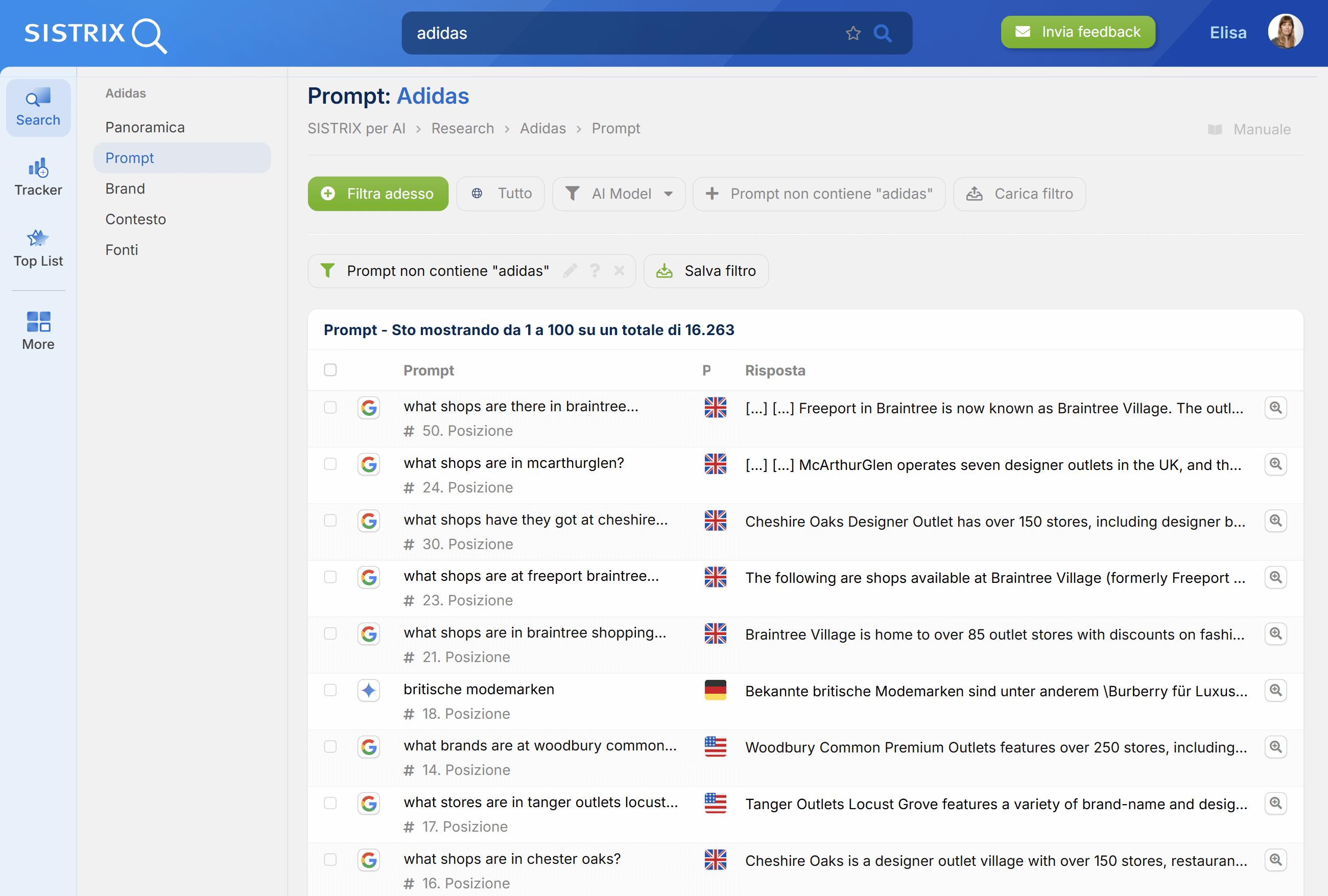
Su SISTRIX, un brand o un’entità possono essere semplicemente inseriti nel campo di ricerca del tool “SISTRIX per AI/Chatbot”: nella sezione “Prompt” troverai tutti i prompt che sono stati interrogati in relazione all’entità inserita. Attivando il filtro “il prompt non contiene [entità]”, visualizzerai solo i prompt in cui il brand è menzionato nella risposta, ma non era esplicitato nella domanda iniziale.
Scopri subito come sfruttare SISTRIX per il tuo business online! Sette giorni per provare l’intero tool, compresi i dati AI, senza alcun costo nascosto, né disdetta necessaria: testa subito SISTRIX gratuitamente.
Riassunto
Il Query fan‑out è un metodo dei nuovi sistemi di ricerca AI in cui le query degli utenti vengono automaticamente scomposte in diverse domande parziali. Per la SEO, questo significa che oggi i contenuti devono essere più ampiamente orientati, più profondamente strutturati e facilmente estraibili dalle macchine.
Con SISTRIX è possibile riconoscere i sottodomini rilevanti, pianificare i contenuti di conseguenza e misurare la propria presenza nelle risposte generative. Strutturando i tuoi contenuti in modo che possano essere utilizzati direttamente come moduli di risposta, aumenterai le tue possibilità non solo di essere trovato, ma anche di diventare visibile come fonte rilevante nelle risposte di ricerca basate sull’AI.
FAQ: domande frequenti sul Query fan-out
1. Qual è il differenza tra Query fan-out e la classica ricerca di keyword?
- La ricerca classica di keyword si concentra su singole parole chiave e sui ranking. Nel Query fan-out, si tratta di riconoscere tutte le domande parziali di una query di un utente e di costruire i contenuti in modo che possano essere acquisiti dai sistemi AI come moduli di risposta.
2. Come riconosco con SISTRIX se un dominio è già visibile per argomenti legati al Query fan-out?
- Utilizza la sezione “Keyword” con il filtro “AI Overview”: a questo punto vedrai le keyword per le quali viene fornita una risposta AI, e se il tuo dominio viene citato come fonte. In questo modo potrai stabilire se i contenuti appaiono già nelle risposte AI e in quale posizione.
3. Quali formati contenutistici sono particolarmente adatti per il Query fan-out?
- Formati come elenchi (Listicles), istruzioni passo passo, tabelle con dati di confronto e blocchi FAQ sono particolarmente adatti, perché offrono unità chiare ed estraibili che un’AI può utilizzare direttamente.
4. Ci sono requisiti tecnici che dovrebbero essere presi in considerazione in modo particolare?
- Sì: oltre a una struttura di pagina fondamentalmente ben curata (HTML semantico), sono importanti i dati strutturati (ad esempio, markup schema.org) e i segnali visibili di attualità e autorevolezza (E-E-A-T).
Prova SISTRIX gratis
- Account di prova gratuito per 7 giorni
- Nessun obbligo, né disdetta necessaria
- Onboarding personalizzato con esperti