
Una nuova proposta sta suscitando discussioni: con il file llms.txt, i SEO potrebbero per la prima volta controllare in modo mirato quali contenuti devono essere elaborati dai sistemi AI come ChatGPT o Gemini. In questo articolo vedremo cosa può fare questo file, quali sono le opportunità e i rischi, e perché vale la pena solo per pochi.
Il file llms.txt è una proposta per un nuovo standard d’interazione tra siti web e sistemi AI. Esso si rivolge specificamente ai cosiddetti Large Language Models (LLM), ovvero grandi modelli linguistici come ChatGPT, Claude o Gemini, che analizzano ed elaborano contenuti provenienti da fonti web accessibili al pubblico.
Tecnicamente, si tratta di un semplice file di testo in formato Markdown che viene archiviato nella directory principale (root) di un sito web. Il suo obiettivo è d’indirizzare in modo mirato i bot AI verso determinati contenuti, in modo simile a quanto fa una Sitemap per i motori di ricerca classici, con lo scopo di aiutare ad identificare più rapidamente i contenuti rilevanti e di alta qualità, rendendoli utilizzabili in modo più efficiente.
A differenza del robots.txt, che regola l’accesso, e della sitemap.xml, che mostra una struttura completa del sito, l’llms.txt serve per i contenuti, permettendo ai SEO di specificare esattamente quali pagine sono particolarmente rilevanti per gli LLM (ad esempio guide, FAQ o articoli di consulenza tematicamente centrali).
Visibilità nei Chatbot: i limiti del file llms.txt
L’idea dietro al file llms.txt è comprensibile: i SEO possono controllare in modo mirato quali contenuti devono essere elaborati dai modelli linguistici come ChatGPT o Gemini. Nella pratica, tuttavia, l’impatto finora rimane limitato perché attualmente i provider maggiori non lo supportano attivamente. Chi vuole capire dove appare effettivamente un brand nelle risposte dei Chatbot AI ha bisogno di dati affidabili, e non di semplici suggerimenti tecnici.
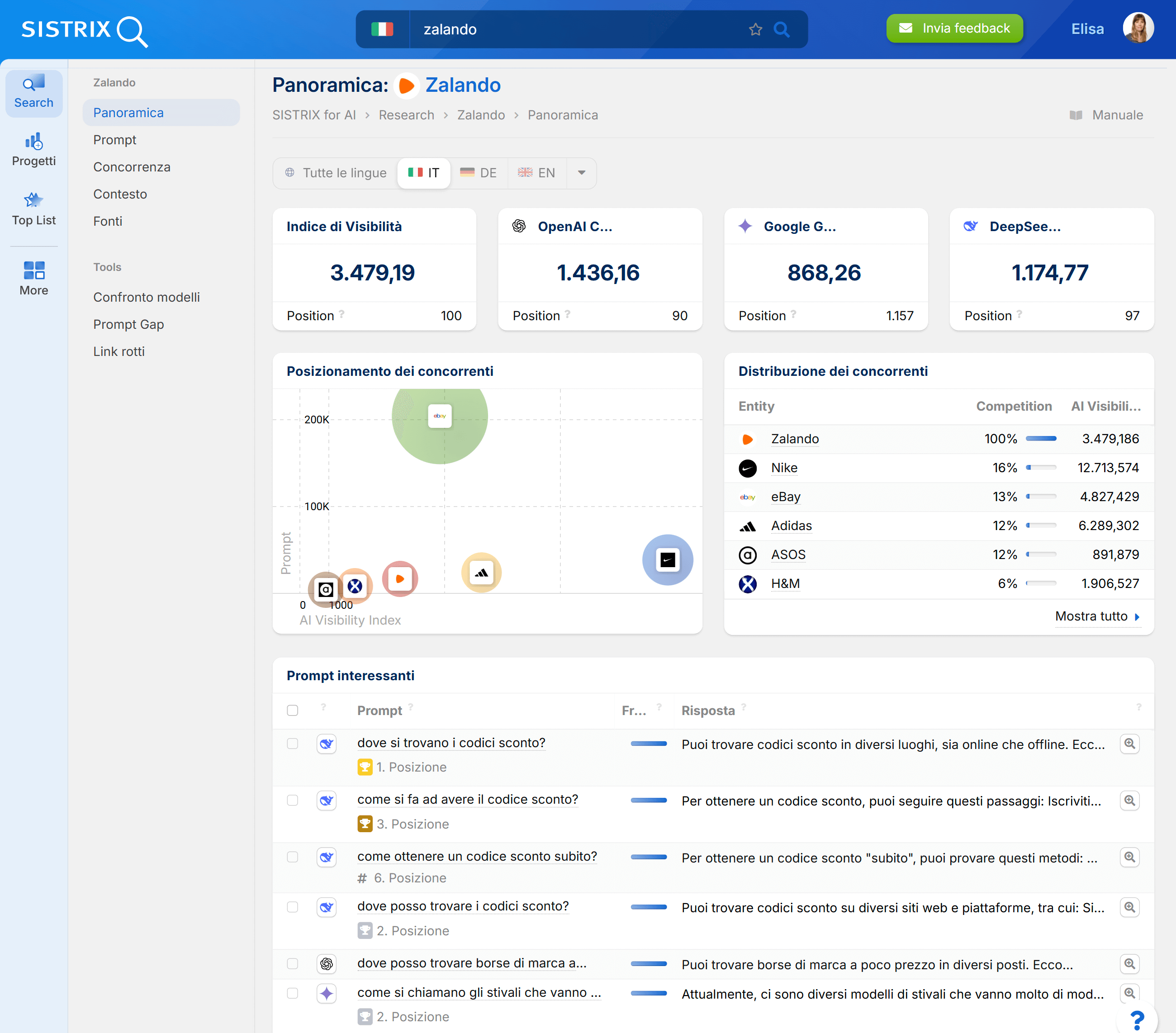
È esattamente qui che interviene la nuova beta di SISTRIX per l’analisi dei Chatbot. Sulla base di dieci milioni di prompt attentamente selezionati, analizziamo per quali domande vengono citati i domini, quanto spesso appaiono i brand e quali contenuti vengono effettivamente elaborati dai modelli AI. In questo modo, è possibile comprendere per la prima volta in modo sistematico quanto un brand sia realmente visibile nei sistemi AI.
Scopri subito come sfruttare SISTRIX per il tuo business online e testa i dati AI! Sette giorni per provare l’intero tool senza alcun costo nascosto, né disdetta necessaria: testa subito SISTRIX gratuitamente.
Chi c’è dietro il file llms.txt?
Chi ha proposto il file llms.txt è Jeremy Howard, co-fondatore del laboratorio di ricerca AI Fast.ai e dell’azienda AI Answer.ai. La prima pubblicazione risale al 3 settembre 2024: su Answer.ai e GitHub, Howard ha presentato il file come una possibile soluzione per fornire agli LLM contenuti web di alta qualità in modo più mirato.
La struttura si orienta sul formato Markdown: titoli chiari, una sezione descrittiva e un elenco di URL che dovrebbero essere elaborati in modo preferenziale dagli LLM. L’idea è quella di creare un indice trasparente e di facile manutenzione per i bot AI.
Esempio di un file llms.txt
# llms.txt – Version 1.0 ## Descrizione esempio.it offre risorse SEO per principianti ed esperti. ## Reference-Content: - https://www.esempio.it/basi-seo - https://www.esempio.it/guida/tool-seo-2026 - https://www.esempio.it/faq/domande-sulla-seo ## Sitemap: - https://www.esempio.it/sitemap.xml ## Direttive: User-agent: * AI-Crawling: Allow AI-Training: Allow AI-Summarization: Allow AI-Generation: AllowRilevanza pratica per la SEO
Il tema del file llms.txt tocca direttamente l’ambito della cosiddetta LLMO, ovvero l’ottimizzazione dei contenuti per i sistemi di risposta basati sull’AI. Un numero crescente di utenti riceve informazioni non più tramite le classiche pagine dei risultati di ricerca, bensì risposte generate direttamente dai modelli linguistici, ad esempio nelle AI Overview di Google o su ChatGPT. Chi vuole essere visibile in questi contesti deve assicurarsi che i propri contenuti siano strutturati, citabili e chiaramente rintracciabili.
L’idea dietro al file llms.txt è proprio quella di supportare questo processo. Anziché doversi far strada attraverso navigazioni complesse, pagine non strutturate o pop-up incorporati, un LLM riceve un elenco preciso di URL curati, in un certo senso una “lista di raccomandazioni” fornita dal gestore del sito stesso.
In teoria, gli LLM possono così:
- Accedere più velocemente ai contenuti pertinenti,
- Gestire in modo più efficiente le finestre di contesto limitate,
- Estrarre in modo più mirato contenuti di alta qualità,
- Rendere il gestore del sito protagonista nella generazione delle risposte.
A ciò si aggiunge un vantaggio tecnico: chi fornisce versioni Markdown per gli LLM separate e snellite dei propri contenuti può ridurre il carico del server, ottimizzare i tempi di caricamento e strutturare la comunicazione con i bot, crendo una sorta di “API-light” per il testo.
Argomenti a favore dell’utilizzo
Anche se il file llms.txt è attualmente solo una proposta sperimentale, ci sono buone ragioni per considerarne l’implementazione:
- Percorsi brevi verso i contenuti migliori: grazie a riferimenti chiari a URL di alta qualità, gli LLM possono trovare più rapidamente i contenuti che sono rilevanti per loro, senza doversi fare strada attraverso percorsi di navigazione o elementi della pagina irrilevanti.
- Basso sforzo tecnico: il file è facile da creare, semplice da gestire e può essere introdotto senza profonde modifiche al CMS o alle strutture SEO esistenti.
- Potenziale di controllo della rappresentazione AI: chi non desidera che contenuti obsoleti appaiano nelle risposte AI, può controllare cosa viene indicato nel file e cosa no.
- Vantaggi tecnici grazie a contenuti “snelliti”: chi ha problemi con il traffico AI può fornire dei file .md con markup ridotto e senza layout visivi, e linkarli nel file llms.txt. Ciò consente di risparmiare larghezza di banda e aumenta la comprensibilità.
- Posizionamento precoce rispetto ai nuovi standard: anche robots.txt, schema.org e AMP sono partiti senza un ampio supporto e si sono poi evoluti in standard consolidati.
Critiche e controargomenti
Allo stesso tempo, ci sono numerose voci che mettono in guardia e forniscono buone ragioni per non implementare affrettatamente il file llms.txt:
- Bassa diffusione: finora meno dello 0,005% di tutti i siti mondiali utilizza il file, quindi non si può ancora parlare di uno standard.
- Mancanza di supporto dai grandi fornitori: Google stesso ha chiarito che il file llms.txt non è attualmente utilizzato da nessuno dei grandi fornitori di LLM. John Mueller ha paragonato il file al vecchio tag meta-keywords, un elemento che è stato completamente ignorato a causa dell’abuso massiccio da parte dei SEO.
- Rischio di abuso: teoricamente, i SEO potrebbero collegare nel file llms.txt contenuti diversi da quelli visibili agli utenti o ai motori di ricerca, creando un potenziale rischio di cloaking.
- Nessun vantaggio SEO comprovabile: attualmente non ci sono indicazioni che il file migliori in alcun modo i ranking o la visibilità. Anche i sistemi di risposta basati sugli LLM apparentemente lo utilizzano poco o per nulla.
- Costi di manutenzione senza chiaro beneficio: chi ha molte pagine deve aggiornare regolarmente il file llms.txt, uno sforzo che non ne vale quasi la pena senza risultati visibili.
Cosa dicono Google, OpenAI e altri?
Google attualmente respinge il file llms.txt definendolo non mirato. Anche OpenAI finora non si è pronunciata ufficialmente a riguardo, sebbene nei logfile si trovino indizi di scansione da parte dell’OAI-SearchBot.
Yoast ha accolto la proposta e offre una generazione automatica nel suo diffuso plugin SEO. Anche alcuni provider più piccoli stanno sperimentando il formato, ma si è lontani da un vero e proprio ecosistema.
Infine, Google raccomanda d’impostare il file llms.txt su “noindex” affinché non appaia nei risultati di ricerca. Ciò rende chiaro che, anche dal punto di vista di Google, il file non è un fattore di ranking, bensì un’integrazione puramente tecnica senza un chiaro beneficio.
Devo quindi implementare il file llms.txt?
La risposta dipende fortemente dal sito in questione: una raccomandazione universale, come al solito, non è (ancora) possibile. Ecco alcuni scenari:
- Per i SEO che amano sperimentare con risorse tecniche e traffico legato all’AI, un test può essere utile. In tal caso, si dovrebbe chiaramente delimitare cosa viene incluso nel file e monitorare l’effetto tramite log o statistiche di scansione.
- Per i siti aziendali classici senza un focus sugli LLM o con una forte attenzione alla visibilità organica su Google, attualmente non c’è alcun beneficio. Qui, lo sforzo dovrebbe essere investito in misure collaudate come la qualità dei contenuti, i Core Web Vitals o i dati strutturati.
- Per le piattaforme con una vasta offerta editoriale, il file llms.txt può essere un livello aggiuntivo per mettere in evidenza contenuti particolarmente citabili, a condizione che questi siano già strutturati e recuperabili in modo ottimale.
Il file llms.txt è una proposta tecnicamente interessante, ma finora ampiamente irrilevante nella pratica. La sua origine da un’azienda vicina all’AI dimostra che, come spesso accade con l’intelligenza artificiale, anche gli interessi strategici ed economici giocano un ruolo importante. Chi si occupa del tema dovrebbe tenerlo a mente e condurre la discussione in modo oggettivo e basato sui fatti.
Attualmente, non c’è un’urgente necessità di agire, ma chi vuole può testare. Chi aspetta che si sviluppino nuovi standard, invece, non commette errori ed eventualmente risparmia investimenti inutili. Contenuti strutturati e citabili, una tecnica pulita e percorsi di navigazione chiari rimangono cruciali, sia per i motori di ricerca che per i modelli linguistici, e questo è il punto fondamentale da ricordare.
Prova SISTRIX gratis
- Account di prova gratuito per 7 giorni
- Nessun obbligo, né disdetta necessaria
- Onboarding personalizzato con esperti