
Un “Large Language Model”, in breve LLM, è un modello linguistico basato sull’apprendimento automatico che, attraverso un addestramento basato su vaste raccolte di testi, è in grado di effettuare analisi, rispondere a input in un linguaggio naturale e generare autonomamente testi coerenti e pertinenti al contesto.
I Large Language Model sono sistemi basati su computer che elaborano il linguaggio su larga scala: essi analizzano schemi linguistici nei testi e generano contenuti basati su probabilità statiche, che spesso appaiono convincenti per i lettori umani anche se il modello non “comprende” il contenuto stesso.
La loro caratteristica distintiva è che vengono addestrati con enormi quantità di dati (tra cui testi provenienti da libri, pagine web, articoli, commenti, ecc.) e in questo modo imparano come funziona il linguaggio: grammatica, stile, contesto, significato e connessioni. Questo però non significa che i modelli linguistici sappiano tutto: sono stati infatti solo alimentati con quantità molto grandi di conoscenza umana e possono attingere unicamente da queste informazioni.
L’evoluzione dei modelli linguistici è iniziata con sistemi semplici basati su regole, in grado di riconoscere solo correlazioni limitate. Successivamente si sono aggiunti modelli che hanno imparato ad elaborare meglio il linguaggio con l’aiuto dell’intelligenza artificiale. Queste prime reti neurali sono state un bel passo avanti, ma non risultavano ancora abbastanza potenti per elaborare testi lunghi o correlazioni complesse.
La vera svolta è arrivata con la cosiddetta architettura Transformer nel 2017, che ha permesso di elaborare in modo efficiente enormi quantità di dati, acquisendo anche correlazioni testuali più lunghe. Su questa base sono nati gli attuali Large Language Model (LLM), che sono notevolmente più potenti, flessibili ed estesi rispetto ai loro predecessori.
L’architettura Transformer gioca quindi un ruolo centrale: permette al modello non solo di concentrarsi localmente, ma di mettere anche in relazione tra loro tutte le parti di un testo (Self-Attention). Ciò consente di acquisire i contesti linguistici in modo molto più completo, risolvere meglio le ambiguità e applicare lo stile e il contesto in modo più corretto. La modernizzazione che ha condotto agli LLM ha permesso, quindi, non solo di aumentare dati e potenza di calcolo, ma anche di migliorare l’architettura del modello in modo fondamentale.
Funzionalità e tecnologia

Addestramento e dati
L’addestramento di un LLM inizia tipicamente con una fase di Pre-Training, paragonabile ad una scuola elementare, dove vengono utilizzati grandi corpus di testo ampiamente distribuiti (tratti da libri, pubblicazioni scientifiche, notizie, forum, ecc.). L’obiettivo in questa fase non è risolvere un compito specifico, bensì apprendere schemi linguistici: come costruiscono le frasi gli esseri umani? Come collegano i pensieri? Come viene generato il significato attraverso le parole? Questa fase è auto-supervisionata: il modello cerca, ad esempio, di prevedere quale parola verrà dopo, o di ricostruire parti di una frase.
Dopo il Pre-Training, segue spesso una fase di Fine-Tuning, in cui il modello viene adattato a compiti o domini specifici. Ad esempio, un LLM può essere addestrato per comprendere particolarmente bene testi legali, supportare conversazioni mediche o interagire con i clienti sotto forma di Chatbot. Inoltre, vengono utilizzate tecniche come l’Instruction Tuning, in cui il modello impara a rispondere a specifiche istruzioni o direttive di stile, e il Reinforcement Learning from Human Feedback (RLHF), in cui il feedback umano viene utilizzato per migliorare la qualità, la comprensibilità e la sicurezza degli output.
Architettura
La maggior parte dei modelli linguistici moderni si basa sulla cosiddetta architettura Transformer. Essa permette al modello di considerare contemporaneamente tutte le parole di un testo e di riconoscere le loro relazioni reciproche. Una componente centrale è la cosiddetta procedura di “Attention“: aiuta il modello a decidere quali parole in una frase sono particolarmente importanti per comprenderne il contesto. In questo modo, il modello può cogliere non solo singoli termini, ma anche il significato e la struttura di un testo.
Quanto un modello sia potente dipende, tra l’altro, dal numero dei suoi parametri. Si tratta dei valori regolabili con cui il modello apprende il linguaggio. Più parametri ha un modello, più correlazioni complesse può rappresentare, ma maggiore è anche lo sforzo tecnico per l’addestramento e l’utilizzo.
Un’altra proprietà importante è la cosiddetta lunghezza del contesto: essa determina quanto testo il modello può considerare in contemporanea. Con contesti brevi, il modello perde rapidamente la visione d’insieme dei passaggi lunghi. I modelli moderni, al contrario, elaborano senza problemi interi articoli o lunghe conversazioni senza perdere il filo conduttore.
Inoltre, esistono LLM che non lavorano solo con il testo, ma possono elaborare anche immagini o altri tipi di dati: si tratta dei cosiddetti modelli multimodali. Essi possono, ad esempio, descrivere un’immagine, interpretare un grafico o rispondere a una domanda che si riferisce a una combinazione di testo e immagine. Questo espande notevolmente le possibilità di utilizzo, ad esempio nella descrizione dei prodotti, nel servizio clienti o nell’analisi di contenuti visivi.
Prompt come interfaccia
L’utilizzo degli LLM si basa sui cosiddetti Prompt. Un Prompt è l’input che un utente rivolge al modello, ad esempio una domanda, un’istruzione o un estratto di testo. Il modello elabora questo Prompt e genera la risposta appropriata corrispondente: pre questo motivo, anche solo piccole differenze nella formulazione possono alterare notevolmente l’output. Tramite i Prompt è anche possibile immettere grandi quantità di dati, ad esempio testi da rivedere o tradurre.
Misurare la visibilità negli LLM con SISTRIX
Gli LLM come ChatGPT, Gemini e DeepSeek stanno cambiando il modo in cui le persone trovano le informazioni e come i brand diventano visibili online. Un numero crescente di query di ricerca che in precedenza portavano a click sui siti web, ora viene risposto direttamente dai Chatbot, dai motori di ricerca AI o dalle AI Overview di Google, causando una diminuzione dei click e un cambiamento nei KPI rilevanti dei siti. Quelli che una volta erano visualizzazioni di pagina e click, nei nuovi sistemi sono citazioni e link nelle risposte dell’AI.
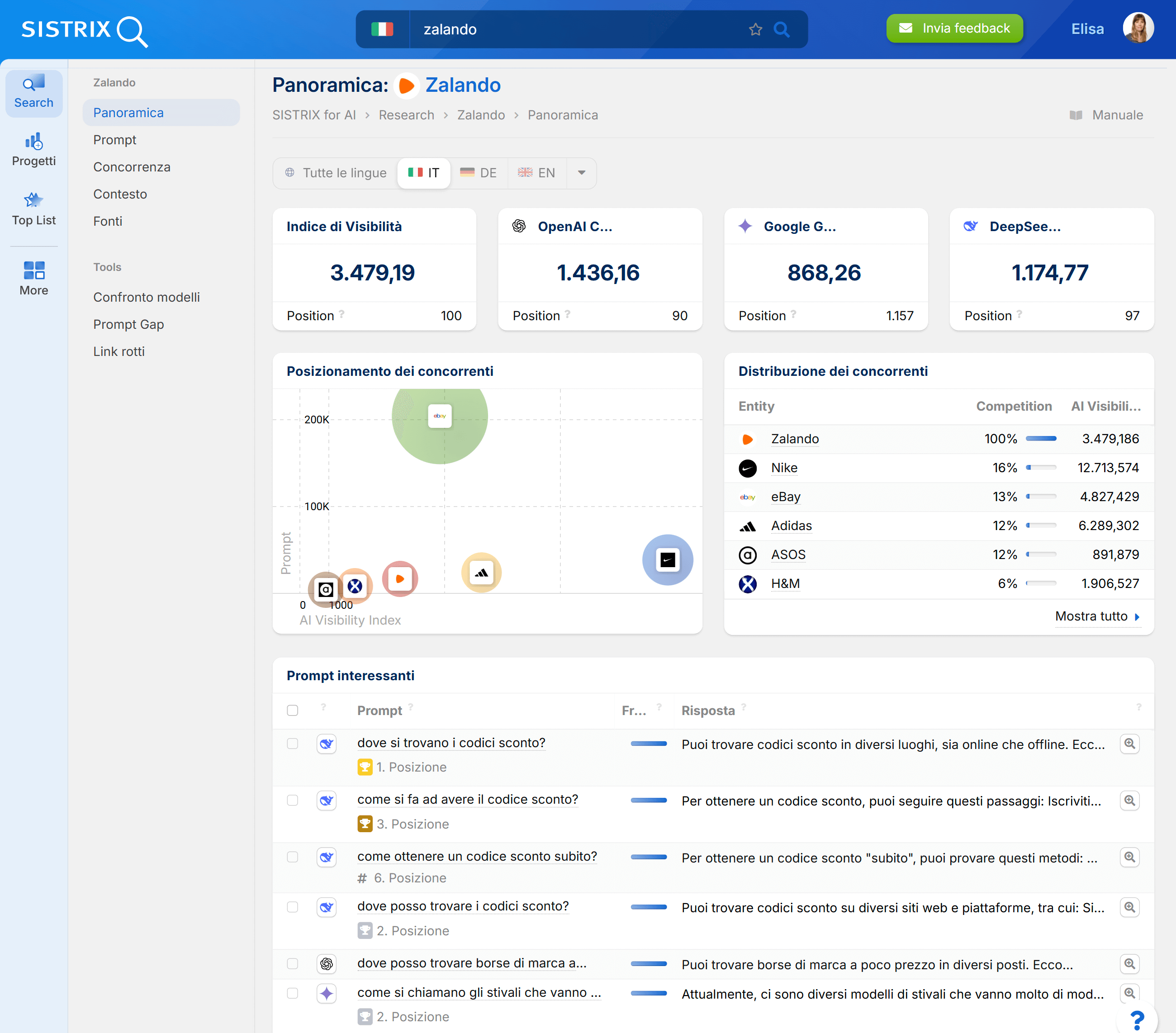
Per misurare queste metriche, esiste il tool Beta AI/Chatbot di SISTRIX. Grazie ad esso potrai verificare facilmente in quali Chatbot viene citato un brand, in quali Prompt appare la propria entità e dove invece sono visibili solo i competitor.
Ricorda però che la maggior parte delle query di ricerca continua comunque a passare attraverso Google, e questo fatto non cambierà dall’oggi al domani. Molte strategie valide per la SEO classica sono la strada giusta anche nel contesto dei nuovi LLM.
Scopri subito come sfruttare SISTRIX per il tuo business online e testa i dati AI! Sette giorni per provare l’intero tool senza alcun costo nascosto, né disdetta necessaria: testa subito SISTRIX gratuitamente.
Campi di applicazione tipici degli LLM
Gli LLM trovano applicazione in molti campi, in parte in scenari quotidiani, in parte in scenari specializzati.
La generazione automatica di testi è uno dei campi di applicazione più evidenti. Che si tratti di articoli di blog, testi di marketing, e-mail o contenuti creativi come storie e poesie: gli LLM possono creare bozze o interi contenuti, facilitando e accelerando l’elaborazione umana.

Nella comunicazione con gli utenti, gli LLM vengono impiegati come Chatbot o assistenti virtuali, rispondendo a domande, dando raccomandazioni, conducendo dialoghi e fornendo supporto. In questo modo migliorano l’esperienza utente e consentono la scalabilità, ad esempio nel servizio clienti.
Gli LLM giocano un ruolo importante anche nell’elaborazione di grandi quantità di informazioni: possono riassumere testi, estrarre concetti chiave da documenti lunghi, rispondere a domande complesse o strutturare informazioni. Tali capacità sono preziose in settori come la scienza, la ricerca, la documentazione aziendale o le perizie legali.
In aggiunta, gli LLM vengono utilizzati per l’analisi e la classificazione dei dati: riconoscimento delle emozioni (Sentiment Analysis), cluster tematici, classificazione dei testi per argomento o tendenza, ma anche identificazione di opinioni, trend o rischi nei social media o nel feedback degli utenti.
Alcuni LLM sono specializzati per domini specifici come la medicina, il diritto o la finanza, anche se in questi ambiti si applicano spesso requisiti più rigorosi in termini di accuratezza, tracciabilità e affidabilità.
Un’area di applicazione in crescita è inoltre l’integrazione degli LLM nei motori di ricerca: invece di fornire solo elenchi di link, essi generano risposte dirette e basate sul linguaggio alle query di ricerca. I motori di ricerca si trasformano quindi in macchine di risposta, facendo nascere una nuova forma di ricerca informativa, in cui non è più la navigazione verso i contenuti a essere in primo piano, bensì la comprensibilità immediata e la semplicità di utilizzo. I modelli agiscono come interfaccia tra utente e conoscenza e stanno cambiando radicalmente il modo in cui i risultati di ricerca vengono percepiti ed elaborati.

Sfide e rischi
Che gli LLM siano estremamente potenti, non c’è alcun dubbio, ma non dobbiamo dimenticarci che causano anche dei rischi.
Un problema fondamentale è la mancanza di “Grounding“: i modelli linguistici calcolano le probabilità ma non hanno comprensione del mondo reale. Anche se sistemi con accesso al web come ChatGPT o Gemini includono informazioni aggiornate dai siti web, essi non verificano i fatti, generando risposte basate puramente sul linguaggio.
Ne conseguono i cosiddetti “Bias” e “Allucinazioni“: i primi riguardano le distorsioni nei dati di addestramento che portano ad output discriminatori o stereotipati, mentre le allucinazioni possono generare informazioni apparentemente plausibili, ma errate, con conseguenze potenzialmente gravi soprattutto in ambiti sensibili come la medicina o il diritto. Gli LLM non possono classificare correttamente i fatti e rispondono a qualsiasi Prompt, anche se formulato con bias o informazioni errate.
Un altro rischio riguarda il fenomeno del “Prompt Injection“, cioè quella pratica in cui gli hacker tentano, tramite input preparati o siti web manipolati, d’indurre i modelli ad eludere le specifiche di sicurezza o a rivelare dati riservati. Questi attacchi sono particolarmente difficili da prevenire, poiché non riguardano il codice, ma il livello del linguaggio stesso.
Non dimentichiamoci inoltre dell’impronta ecologica che lasciano gli LLM: l’addestramento e il funzionamento di modelli di grandi dimensioni consumano enormi quantità di energia e di risorse di calcolo.
A ciò si aggiungono le incertezze legali, come le questioni relative al diritto d’autore, alla protezione dei dati e alla proprietà dei testi generati. Infine, esiste anche il rischio di abuso: gli LLM possono essere utilizzati per la diffusione di disinformazione, spam o contenuti manipolativi.
Le opportunità di questa tecnologia sono certamente enormi in alcuni settori, ma solo se i rischi che ne conseguono vengono gestiti con regole chiare, trasparenza e ricerca.
Esempi di Large Language Model popolari
Tra gli LLM più noti rientrano i seguenti:
- Modelli GPT (OpenAI): sono tra i più utilizzati. Offrono prestazioni elevate nella produzione di linguaggio generativo e godono di un ampio supporto tramite strumenti, integrazioni e risorse della community.
- Modelli LLaMA (Meta): sono spesso aperti (almeno in parte), vengono utilizzati nella ricerca e in scenari d’impiego specializzati, e consentono adattamenti a requisiti specifici.
- Gemini (Google DeepMind): è una famiglia di modelli che esiste dal dicembre 2023 ed è considerata il successore di LaMDA e PaLM. Gemini comprende varianti come Gemini Ultra, Gemini Pro, Gemini Flash e Gemini Nano. Si tratta di modelli multimodali, ovvero che possono elaborare, oltre al testo, anche altre modalità come le immagini. Una caratteristica particolarmente notevole di Gemini è la sua finestra di contesto molto ampia.
- Claude (Anthropic): un modello linguistico sviluppato dal 2023. Si basa sull’approccio della “Constitutional AI” (AI Costituzionale), in cui il comportamento del modello è controllato tramite un insieme di regole prestabilite. Claude è apparso in diverse generazioni (Claude 1, 2 e 3) ed è in continuo sviluppo.
LLM e motori di ricerca
Con la crescente potenza degli LLM nasce una domanda centrale attualmente oggetto d’intensa discussione: i Large Language Model sostituiranno i motori di ricerca classici?
I motori di ricerca tradizionali come Google o Bing si basano essenzialmente sul crawling, sull’indicizzazione e sulla valutazione delle pagine web. Gli utenti inseriscono termini di ricerca, ricevono un elenco di risultati e cliccano sui contenuti pertinenti. Questa interazione è orientata all’informazione, ma è frammentata: l’utente rimane responsabile di filtrare le informazioni, verificare le fonti e combinare i contenuti da solo.
Gli LLM, al contrario, offrono un’interfaccia diretta e basata sul linguaggio, che semplifica l’usabilità: non forniscono elenchi di link, bensì risposte (presumibilmente) complete, spesso con riassunti, argomentazioni o contesto. L’esperienza utente cambia: al posto di “Trova informazioni su X” ora è in primo piano “Spiegami X”, spostando l’azione dal “Cercare” al “Comprendere“. In molti scenari “univoci”, cioè per domande per le quali esiste una sola risposta corretta (come semplici domande di conoscenza, definizioni di termini o istruzioni pratiche) gli LLM sostituiscono già oggi quasi completamente la ricerca web classica.
Questo cambia anche il comportamento dei provider. Ad esempio, a marzo 2025 Google ha cominciato ad integrare componenti LLM direttamente nei risultati di ricerca con le sue AI Overview, mostrando risposte generate dall’AI al di sopra dei risultati classici e sperimentando interfacce basate sul dialogo. Bing, con l’integrazione della tecnologia GPT su “Bing Chat”, ha compiuto un passo simile in anticipo, mettendo Google sotto pressione. Anche startup come Perplexity.ai puntano completamente su un’esperienza di ricerca supportata da LLM, che include le fonti, ma è trasmessa principalmente attraverso il linguaggio.
Al contempo, i motori di ricerca classici rimangono rilevanti, in particolare in ambiti in cui il controllo delle fonti, l’attualità e la trasparenza sono cruciali. Gli LLM generano infatti risposte scorrevoli, ma non sempre forniscono prove verificabili o contenuti aggiornati. Proprio per argomenti di stretta attualità, ricerche complesse o informazioni legalmente vincolanti, la ricerca tramite fonti collegate resta indispensabile.
A lungo termine, si delinea un’ibridazione: motori di ricerca e LLM si fondono. L’utente riceve risposte generate dall’AI con citazioni delle fonti, ma può contemporaneamente approfondire la ricerca, contestualizzare o verificare. Questo sviluppo non è una soppressione, bensì un riallineamento del processo di ricerca, dal modello del click alla struttura del dialogo, dall’elenco di URL alla risposta alla pari.
Per la SEO questo significa che i contenuti devono diventare non solo leggibili dalle macchine, ma anche “comprensibili ai modelli”: struttura, chiarezza, autorevolezza e contesto acquisiscono ulteriore importanza. I professionisti SEO devono inoltre prepararsi che i loro contenuti avranno sempre meno portata (reach), poiché per molte risposte AI (anche se hanno una sola risposta corretta) i click non sono più necessari. Ciò però non significa che questa metrica scomparirà del tutto dalla SEO.
Prova SISTRIX gratis
- Account di prova gratuito per 7 giorni
- Nessun obbligo, né disdetta necessaria
- Onboarding personalizzato con esperti