

Il portale del Comitato per la programmazione e il coordinamento delle attività di educazione finanziaria “quellocheconta.gov.it” ha subito una brusca frenata nelle pagine dei risultati di Google, perdendo più del 90% della sua visibilità online. Vediamo insieme questo caso studio.
Un portale per i cittadini
Era il 2018 quando Banca d’Italia annunciava quellocheconta.gov.it, il nuovo “portale pubblico di educazione finanziaria, assicurativa e previdenziale” il cui scopo è di aiutare i cittadini “a prendere decisioni consapevoli nel campo della finanza personale e familiare, dell’assicurazione e della previdenza.” (fonte).
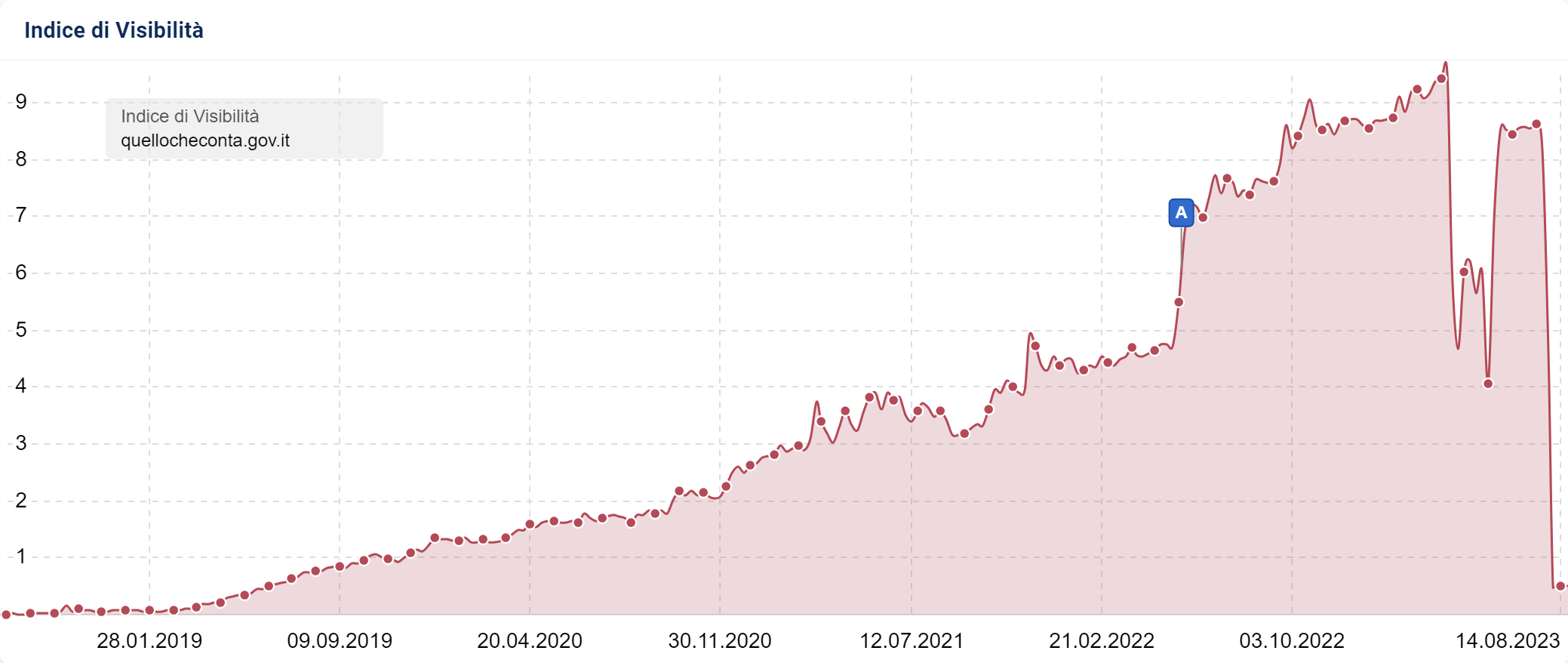
Come vediamo dall’Indice di Visibilità, fino a marzo 2023 il sito era in costante crescita, con una visibilità di 9 punti e una bella spinta dal Core Update di maggio 2022. A inizio aprile il sito subisce una brusca frenata, perdendo metà della sua visibilità in una settimana. Dopo un buon recupero, a luglio crolla definitivamente arrivando a meno di 1 punto, con una perdita di più del 90%.
Una directory come homepage principale
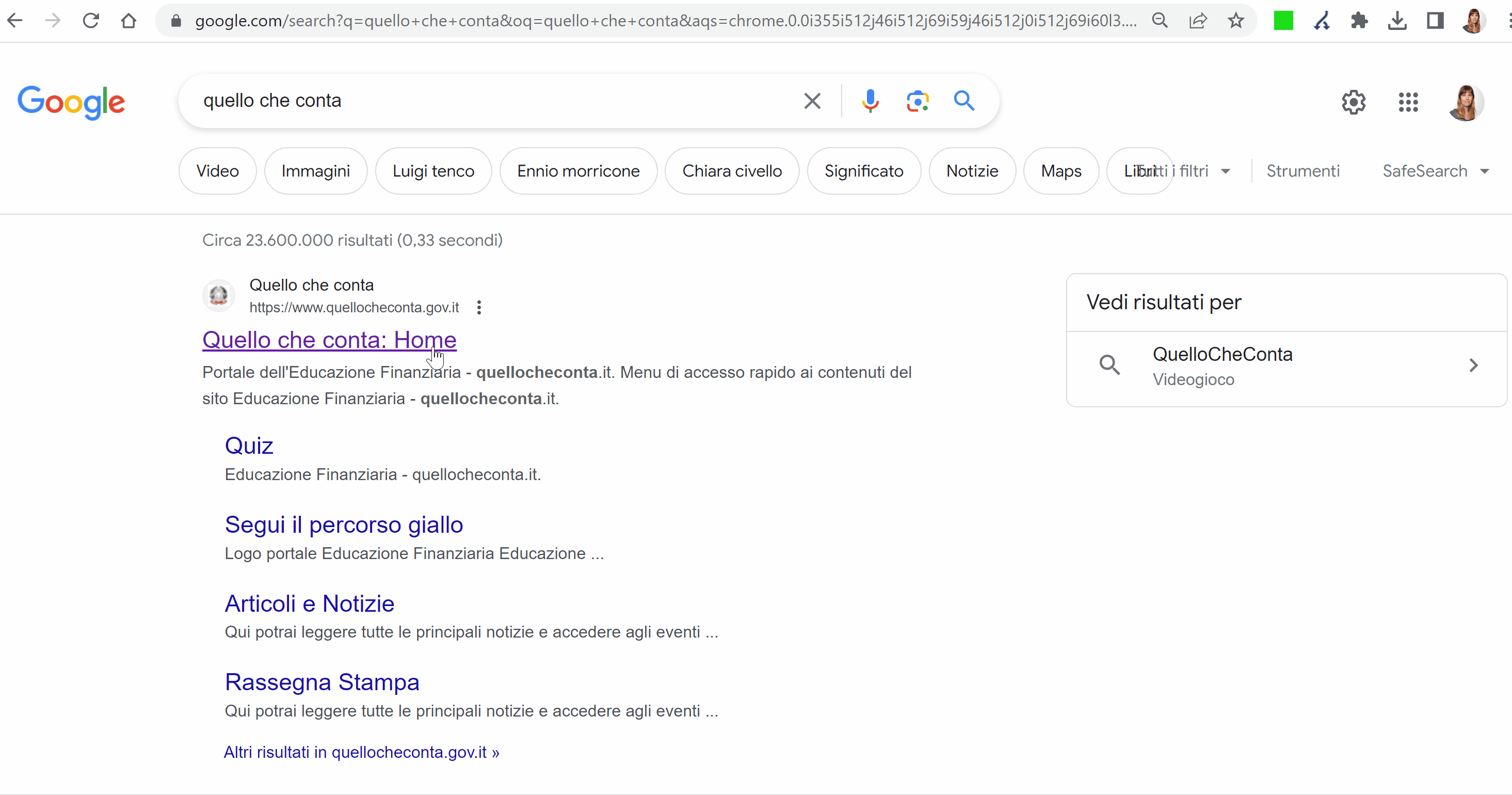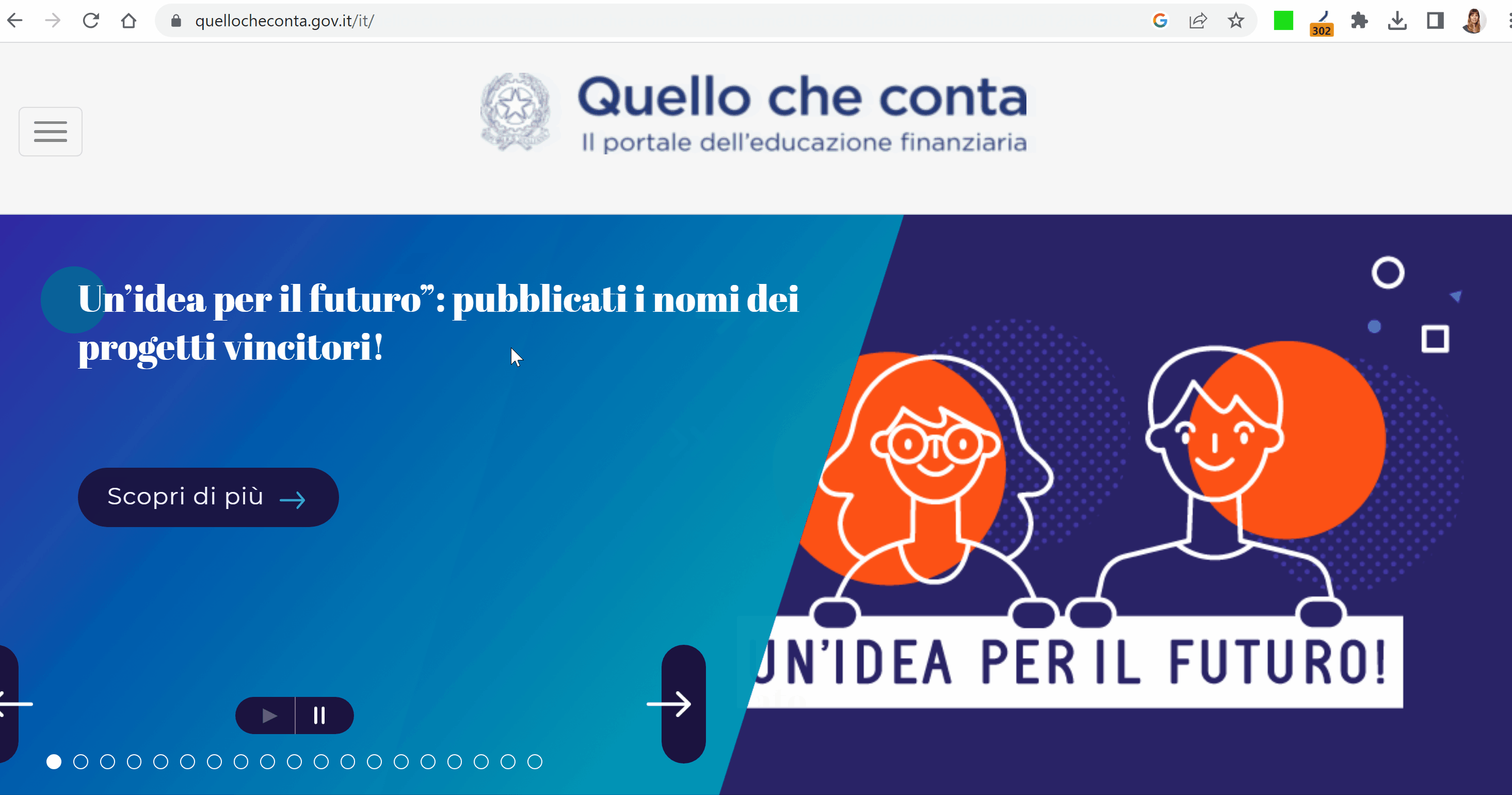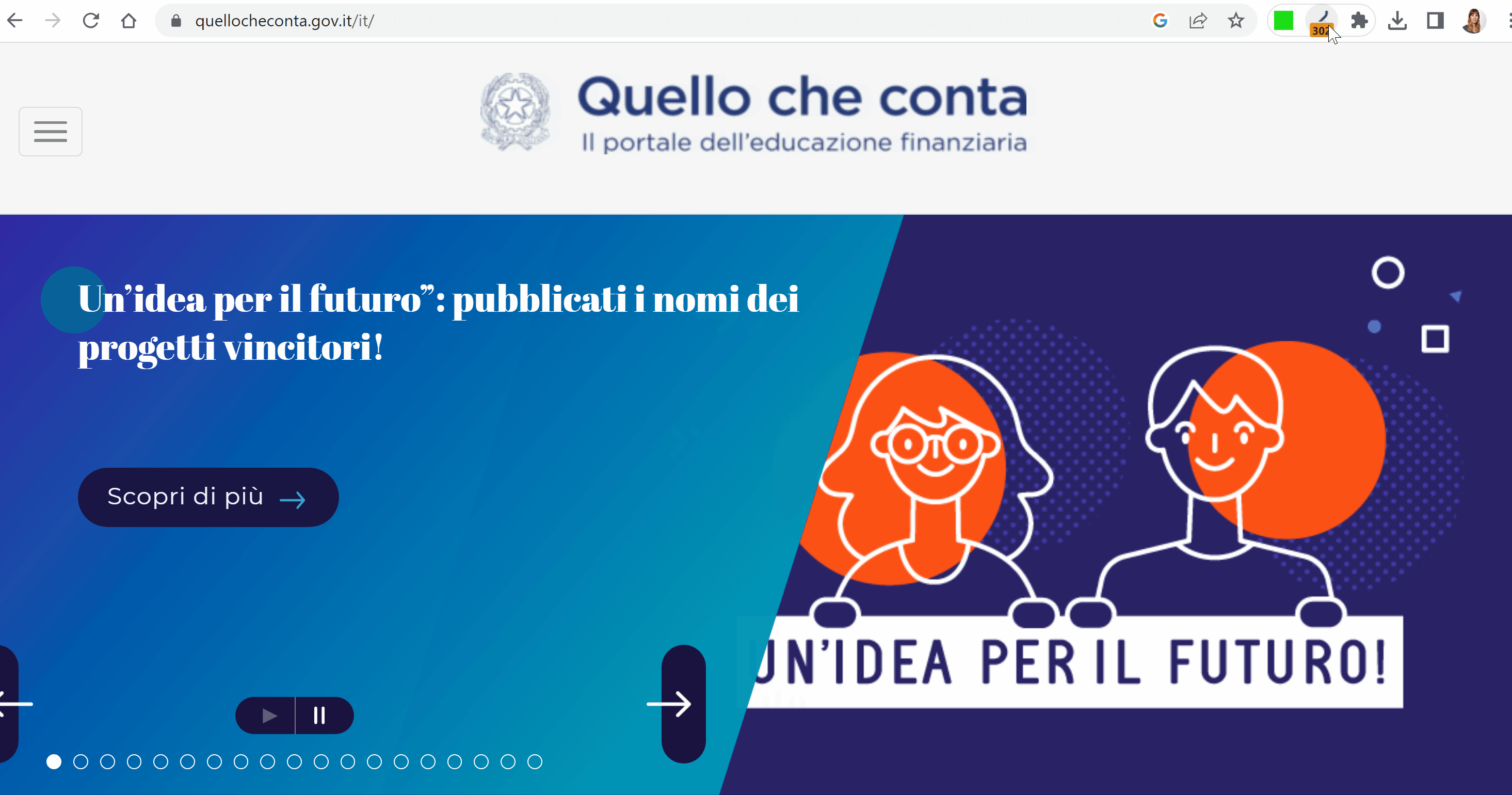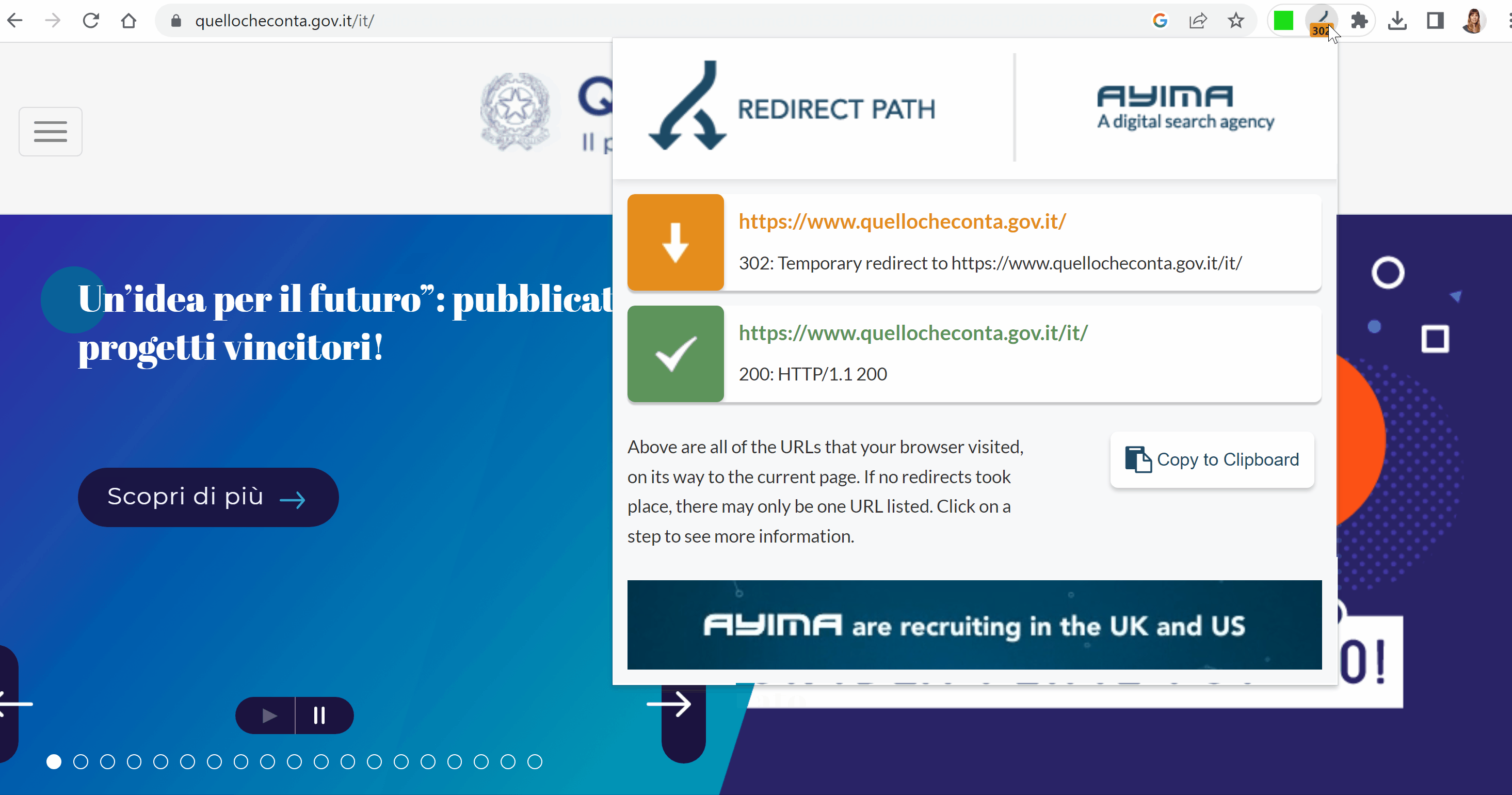
La prima cosa curiosa all’apertura del sito è che la homepage viene redirezionata alla directory quellocheconta.gov.it/it/ via Redirect 302. Nella teoria, questo indicherebbe dei lavori in corso temporanei, perché Google sconsiglia di usare un Redirect 302 per cambiamenti permanenti.
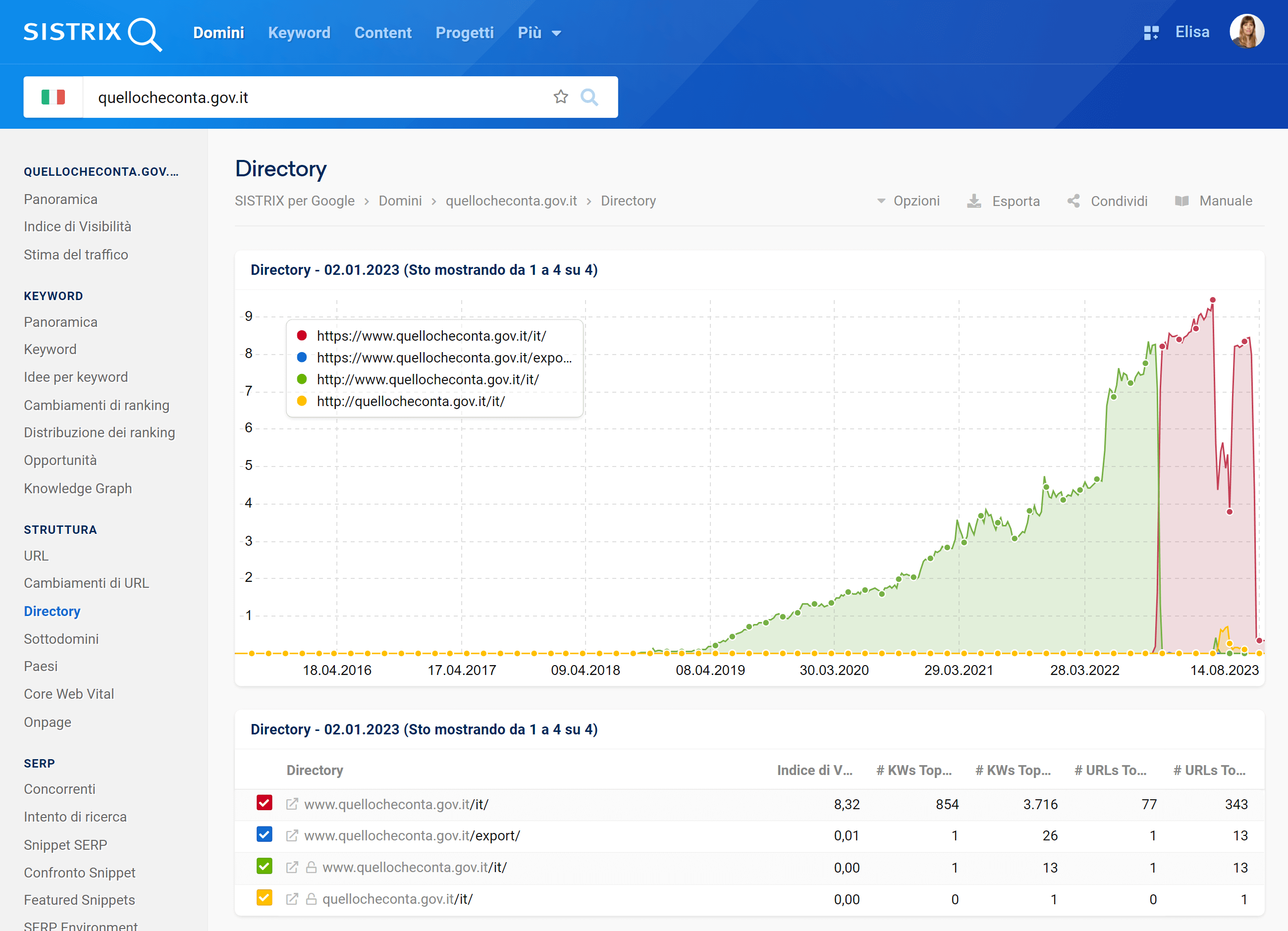
In realtà, è proprio la directory /it il problema, perché è stata proprio la sua ricaduta a trascinare giù l’intero dominio. Anzi: la directory sembra essere quasi scomparsa da Google.
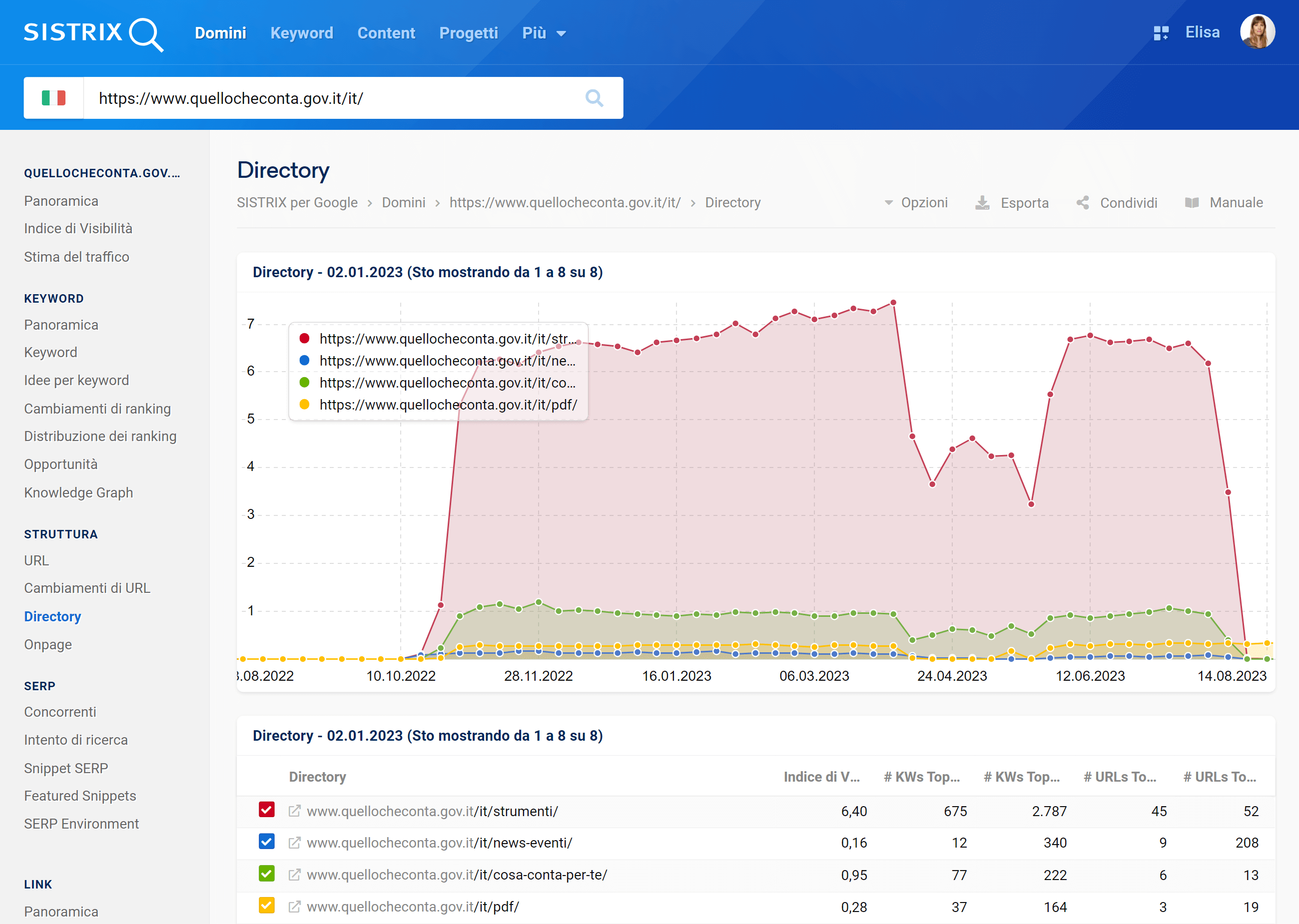
Di questa directory sembra posizionarsi ormai solo la sezione /pdf/, mentre /strumenti/ (la sottodirectory posizionata meglio) è bruscamente crollata.
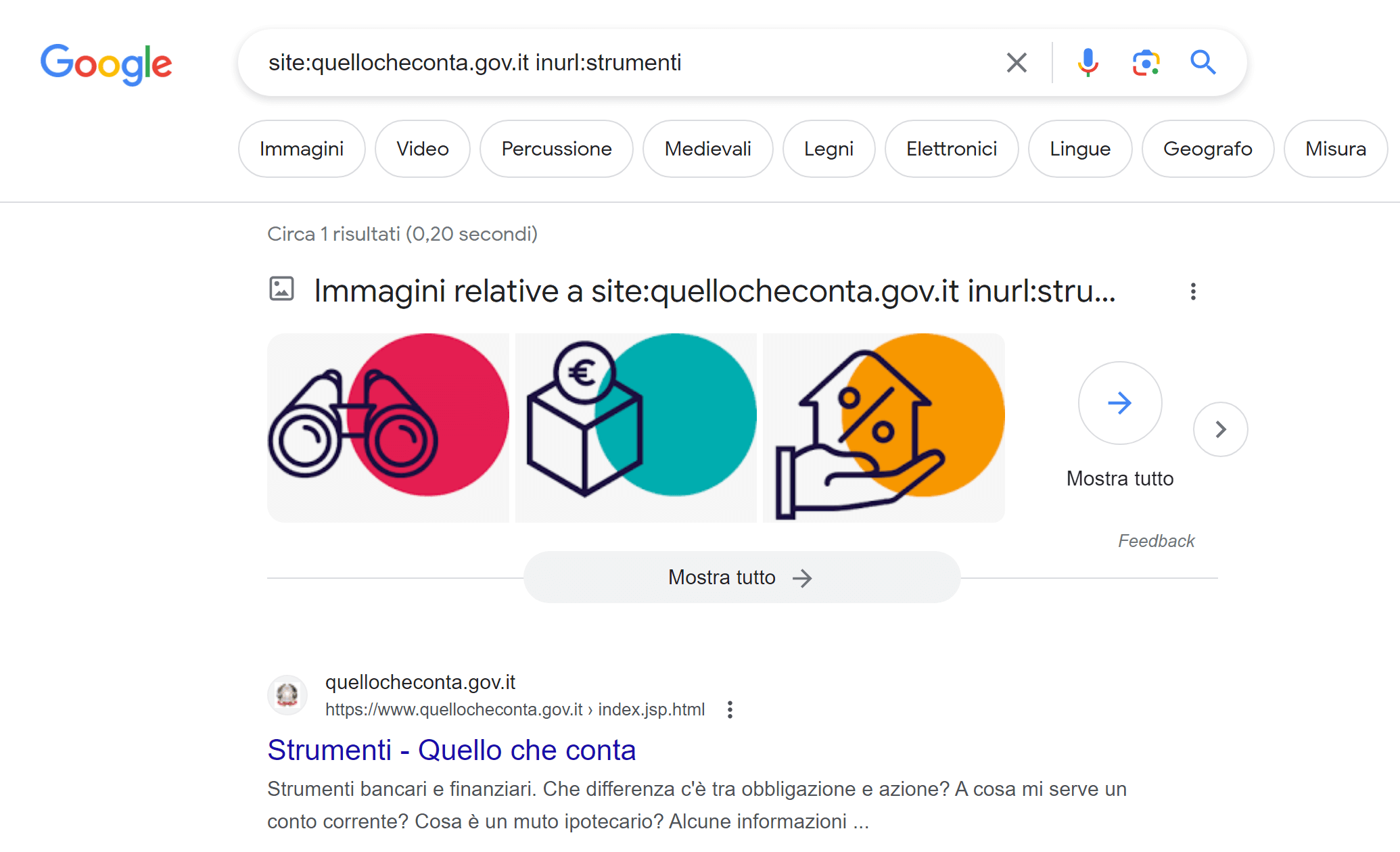
Cercandola con il comando :site su Google, visualizziamo infatti solo 1 risultato.
Il problema, chiaramente di natura tecnica, in questo caso non deriva dal robots.txt.
Le perdite di ranking
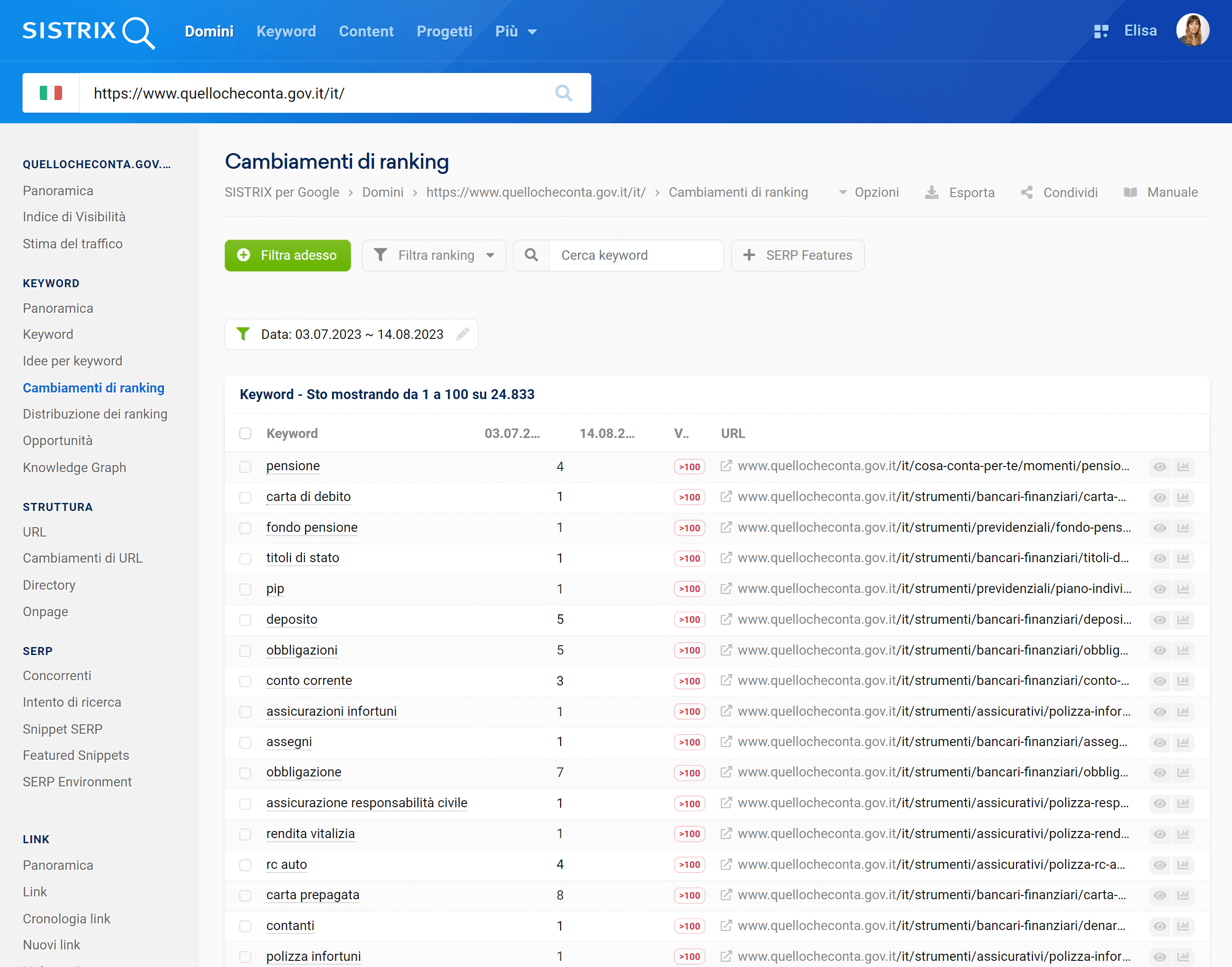
Oltre alla visibilità, il sito ha perso un’elevata quantità di ranking: in un mese, sono più di 24.000 i posizionamenti andati persi, e 3.166 di questi erano in prima pagina.
A prima vista, le pagine sembrerebbero tutte raggiungibili e indicizzate, e rimandano uno status code 200.
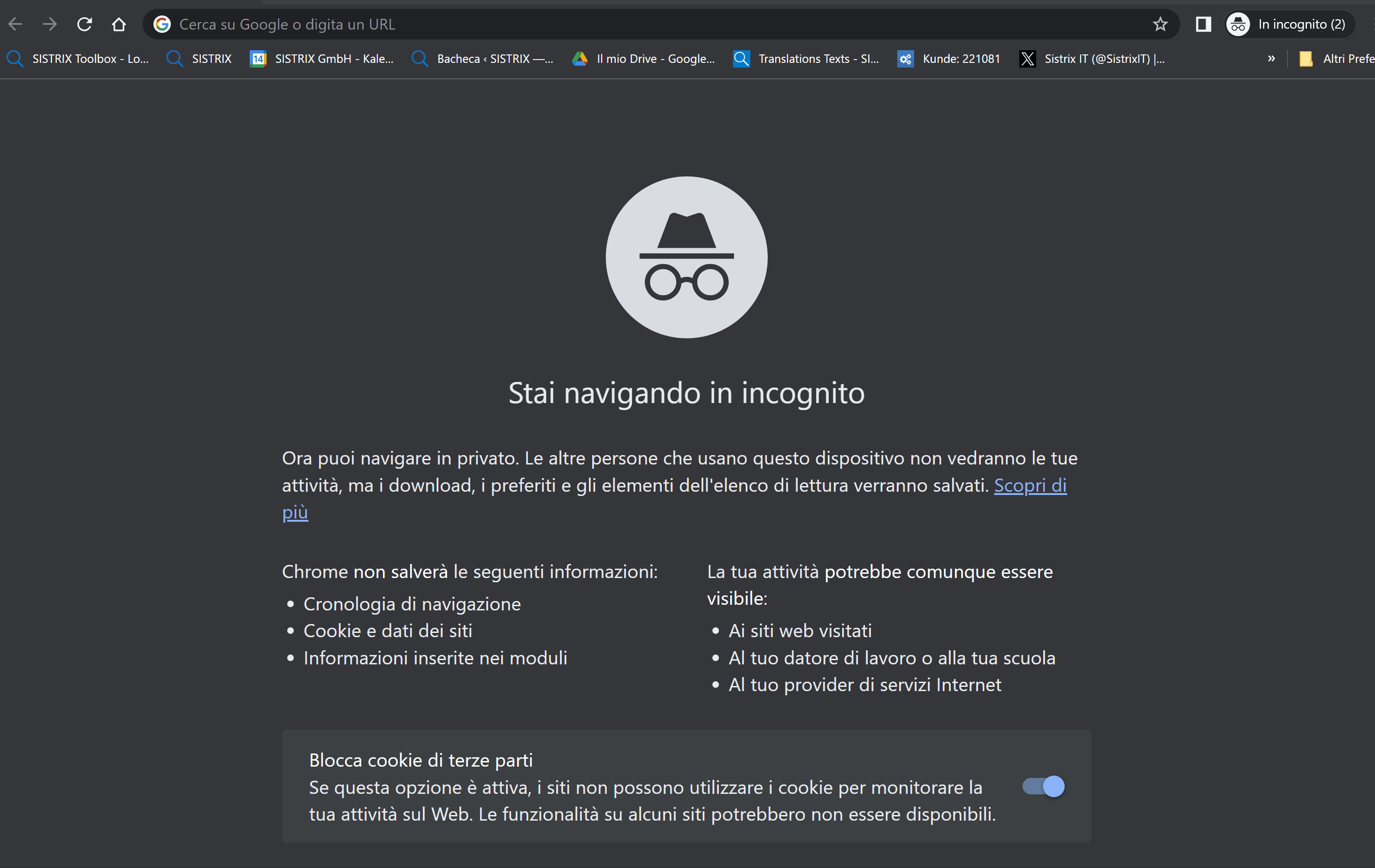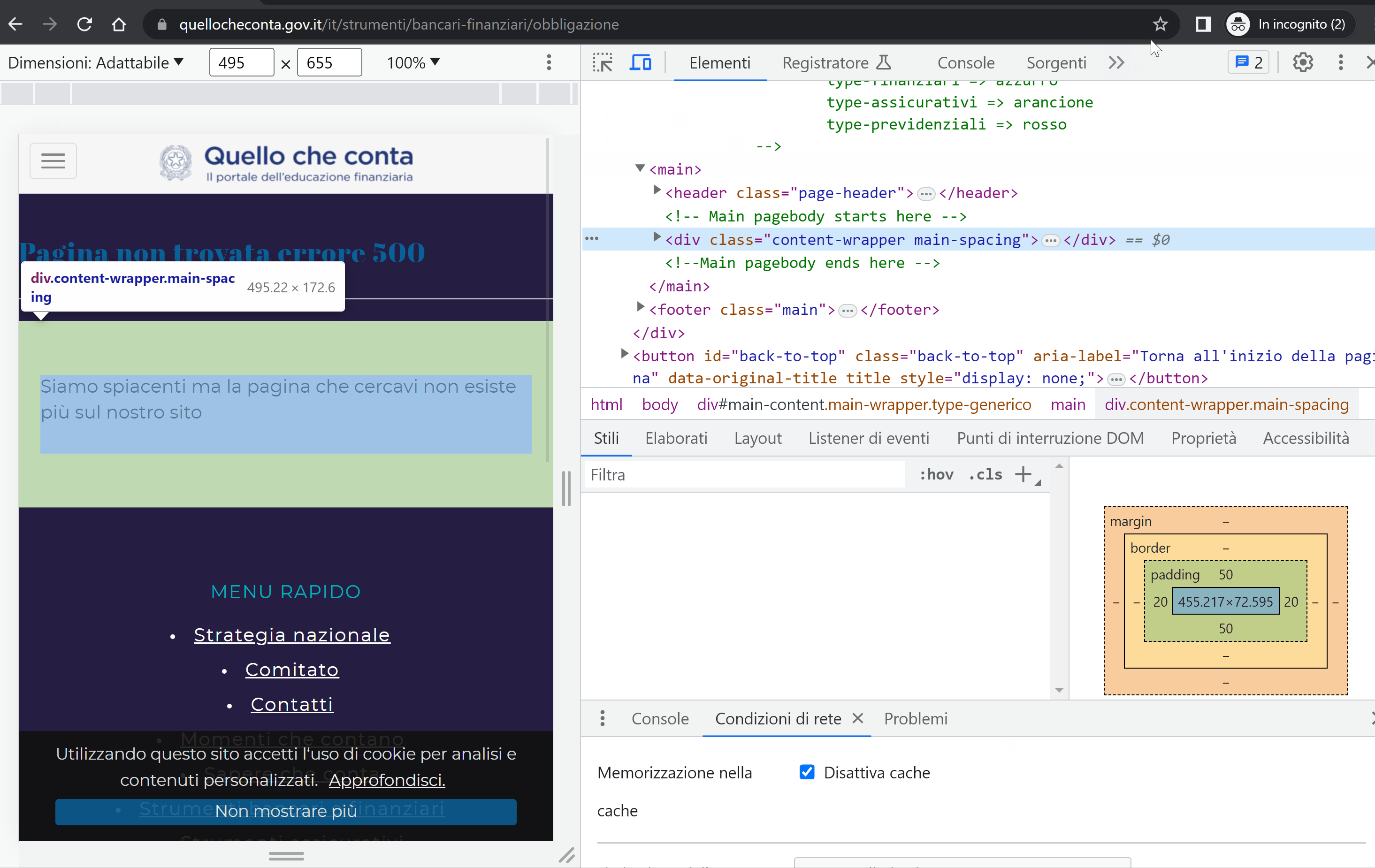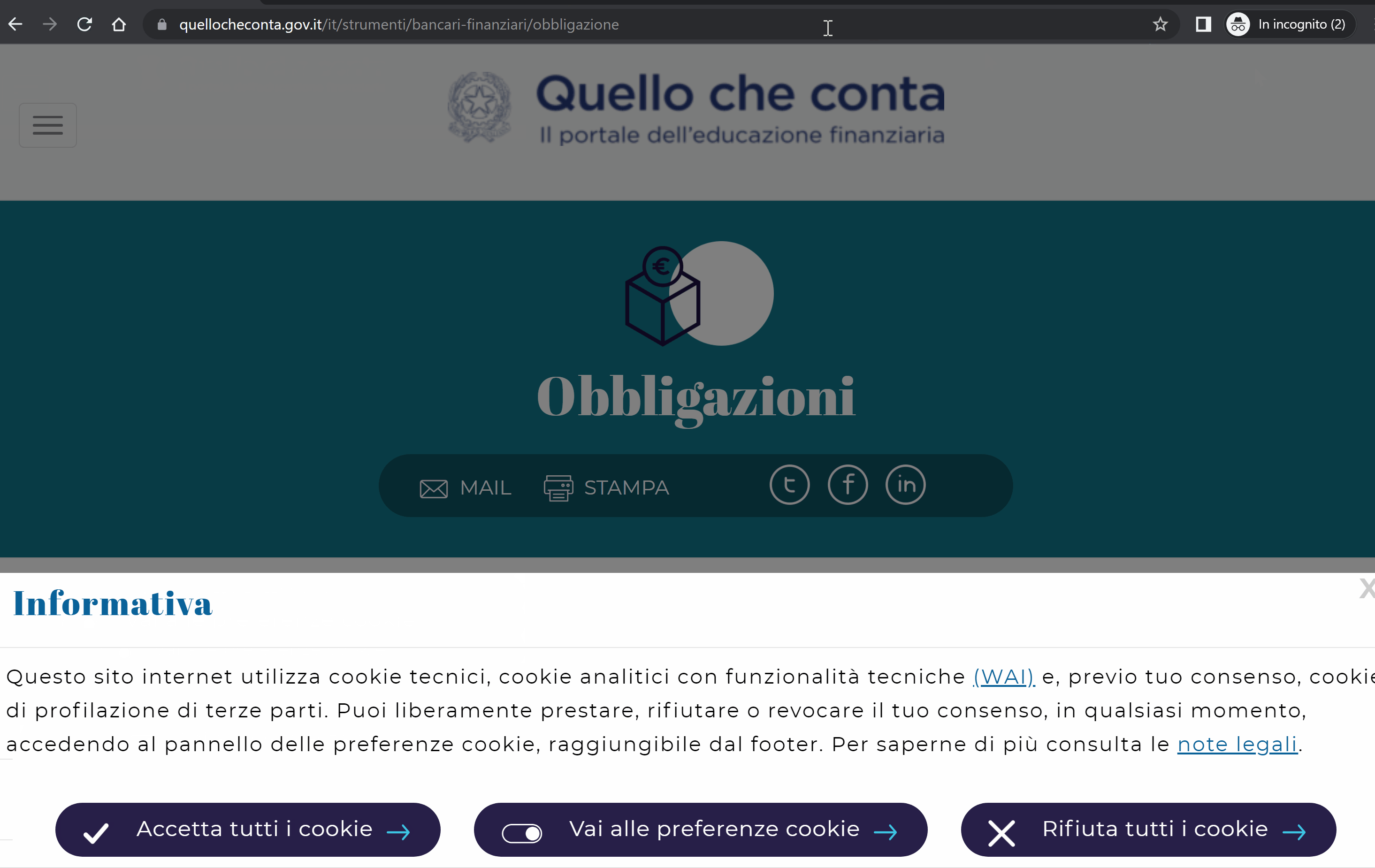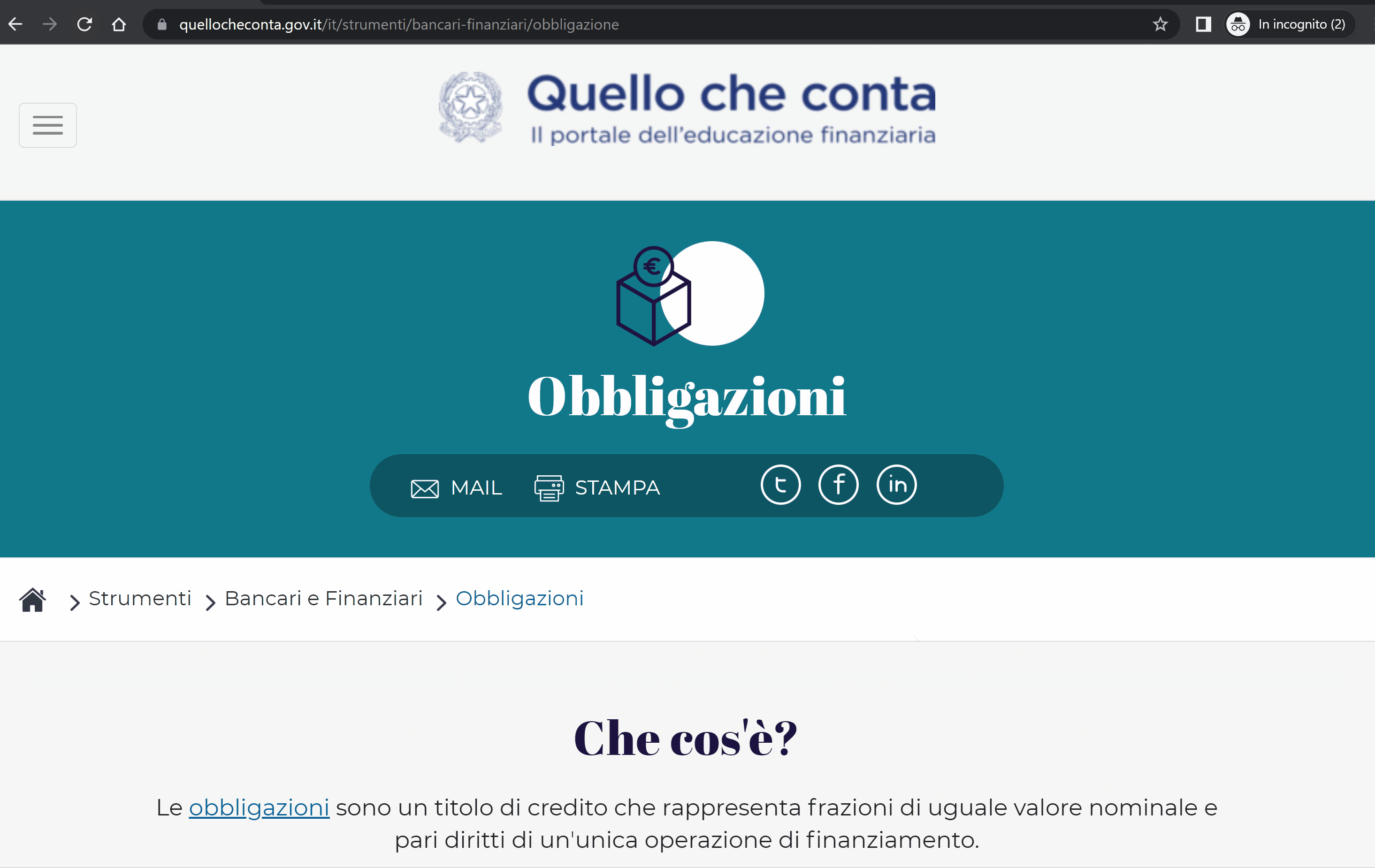
Eppure, grazie ad un progetto Onpage, scopriamo che il crawler di SISTRIX (che simula Googlebot) è riuscito a scansionare solo 29 URL della directory.
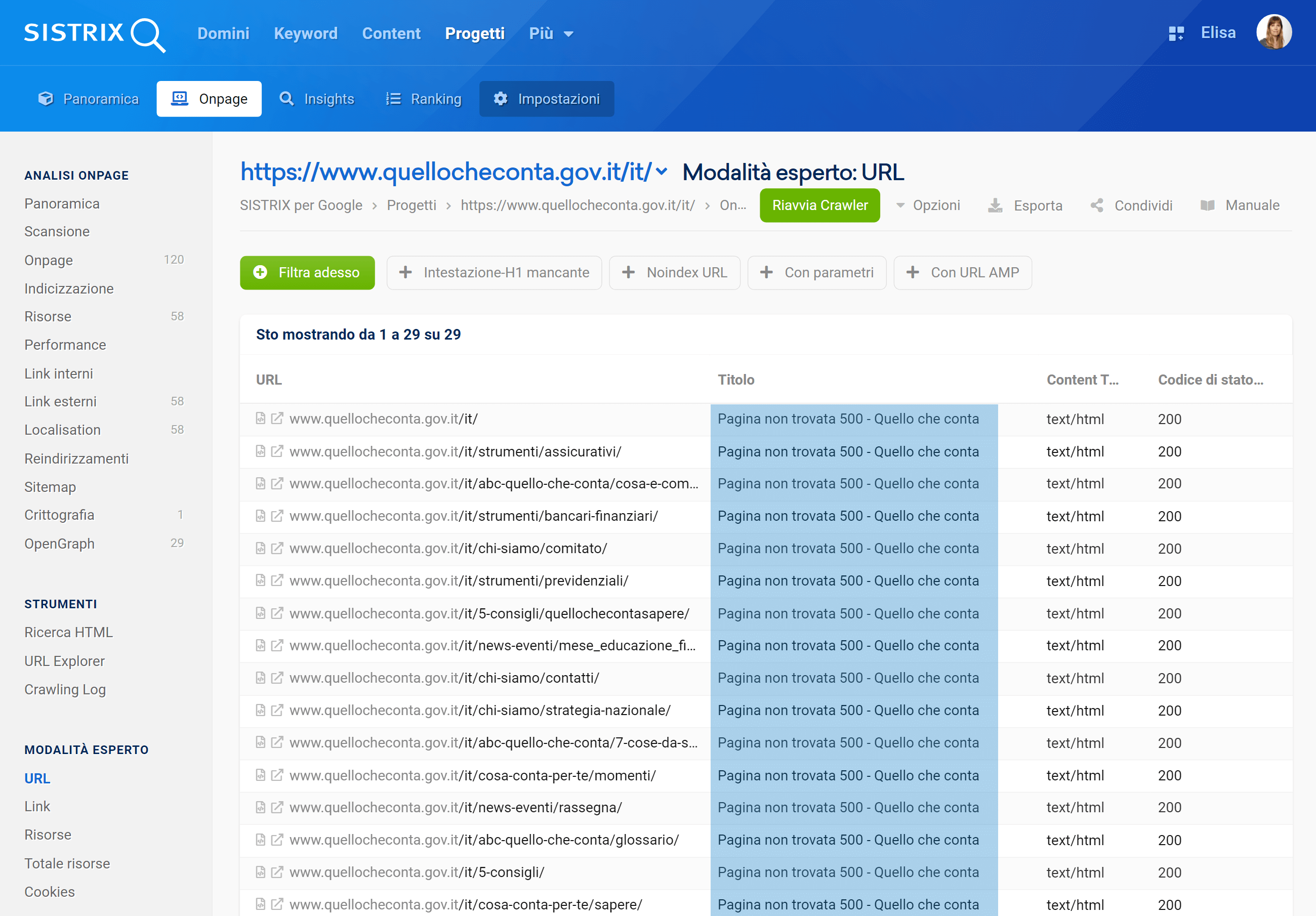
Le pagine scansionate dal crawler di SISTRIX sono raggiungibili se aperte e rimandano un codice di stato 200, ma il loro Title è sempre “Pagina non trovata 500 – Quello che conta”, e, subito sotto, “<!– INSERIRE TITLE PAGINA COERENTE CON IL CONTENUTO –>”.
Ne vediamo un esempio qui sotto:
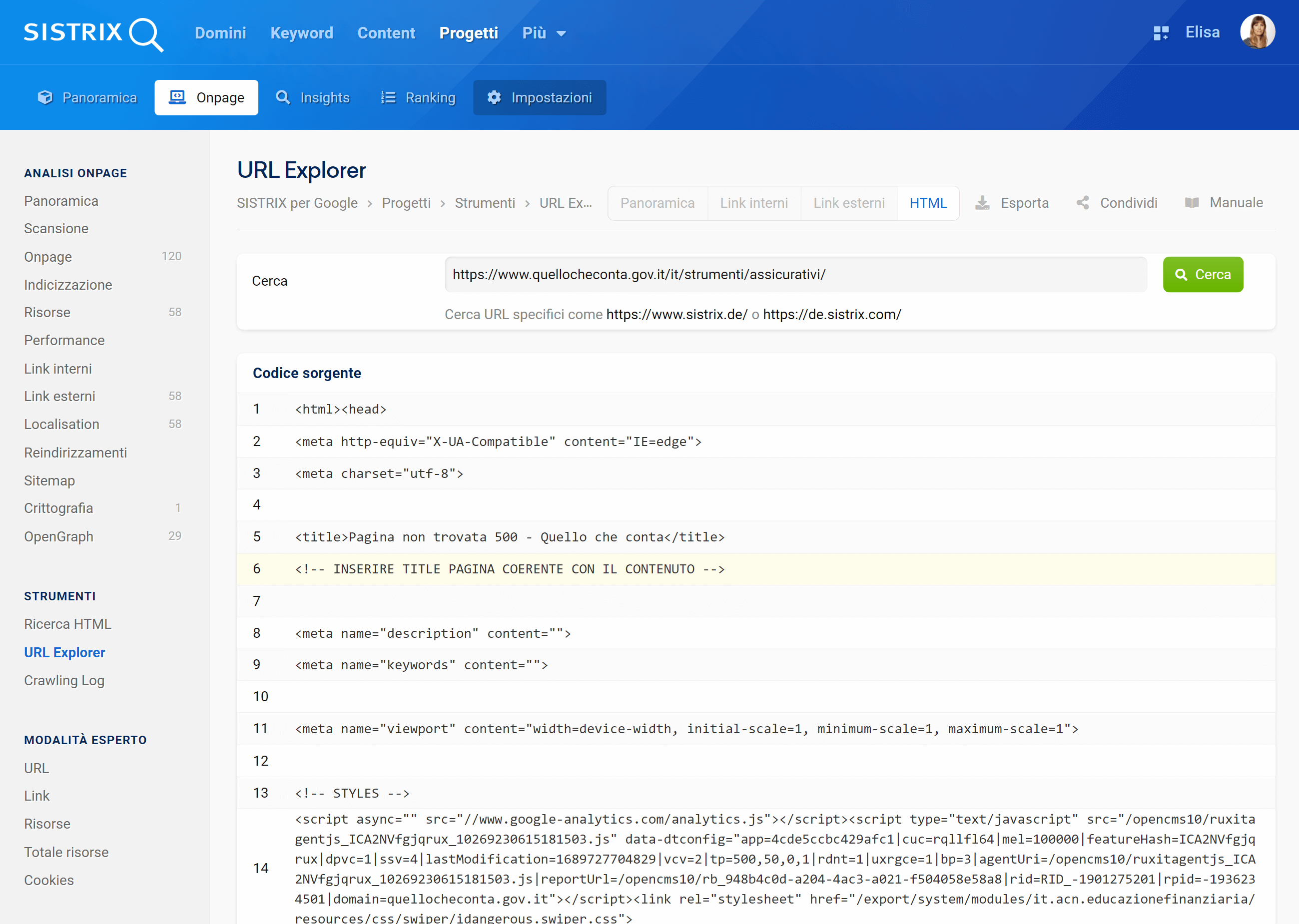
Osservazione 1: una pagina, due aspetti diversi
Usando il “Test di ottimizzazione mobile” di Google giungiamo alla stessa conclusione: le pagine sono raggiungibili e non mostrano alcun errore, ma se si apre la sezione “Screenshot” per vedere come appaiono, il tool mostra una versione completamente differente.
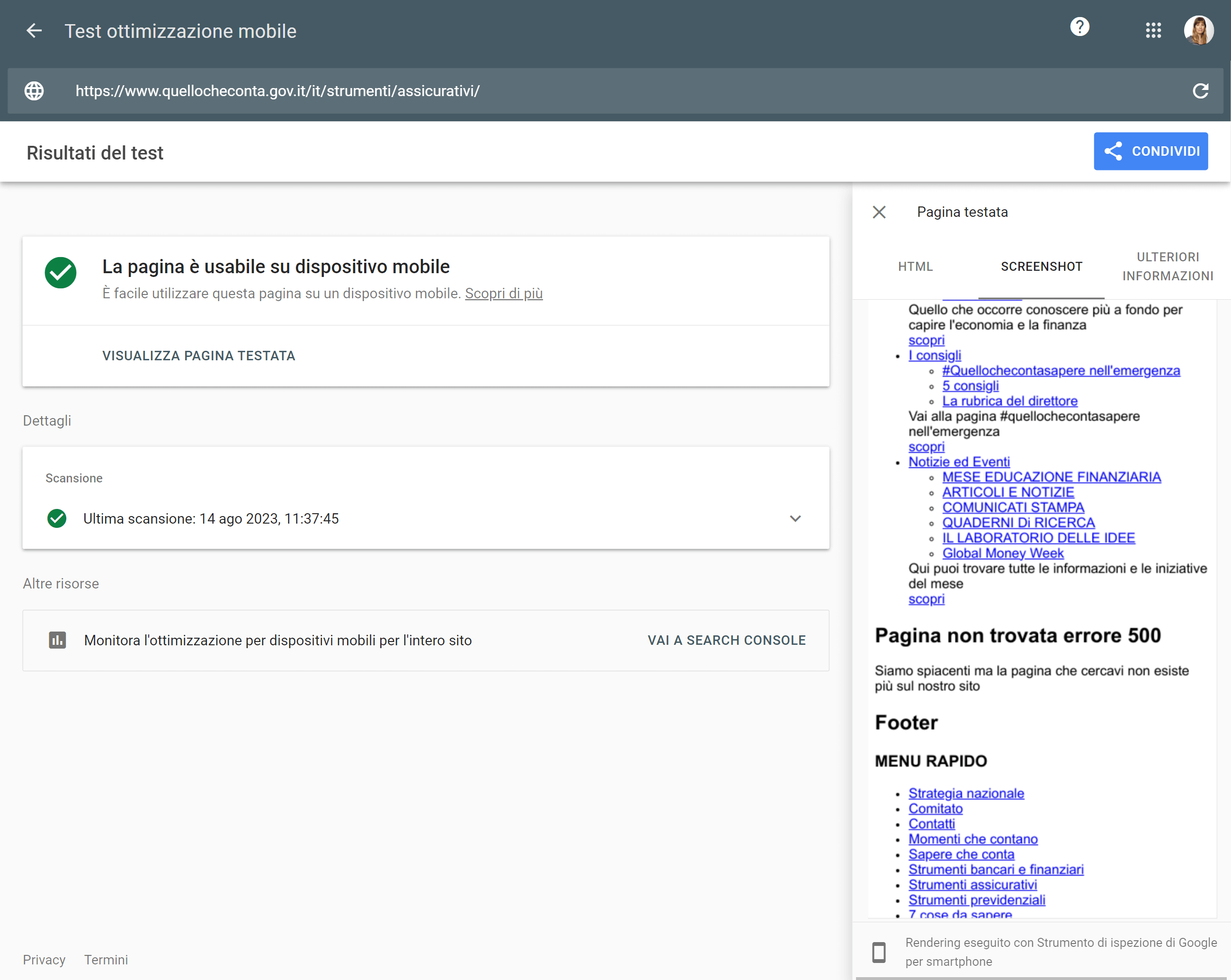
È quindi possibile che la versione del sito visualizzata dagli utenti sia differente rispetto a quella fornita ai bot, e che quindi Google riceva un codice di stato 500 invece di un 200 (una sorta di Cloaking al contrario). Questo comporterebbe una perdita di ranking e visibilità perché il motore di ricerca considererebbe le pagine come non raggiungibili e quindi non adeguate per gli utenti che navigano le SERP.
Osservazione 2: Redirect via Javascript e problemi del server
Disattivando Javascript, il menù di navigazione del sito è totalmente inutilizzabile perché i link interni e i redirect si basano su questa tecnologia.
In realtà, Googlebot è comunque in grado di raggiungere le pagine secondarie attraverso altri tipi di link contenuti nelle pagine, oltre al fatto che John Müller aveva assicurato che Googlebot può seguire i redirect Javascript.
È quindi poco probabile che sia questo il motivo vero e proprio della ricaduta.
Abbiamo però notato che, aprendo una pagina del sito in incognito per la prima volta, visualizziamo un “Errore 500“: tale errore però è fittizio perché scritto testualmente, e la pagina riporta in realtà un codice di stato 200 (come dimostrato dai Chrome Developer Tools). Ricaricandola, mostra invece il contenuto vero e proprio.
Di seguito un esempio:
Da qui sono deducibili problemi interni legati al server che non consentono a Googlebot di vedere il vero contenuto, portandolo a considerare la pagina come un Soft 404.
Questo spiega perché il Test di Ottimizzazione Mobile non rileva alcun problema di usabilità.
Conclusione
Il sito quellocheconta.gov.it sta andando incontro a uno o più errori tecnici gravi che hanno quasi azzerato la sua visibilità nelle pagine dei risultati di ricerca di Google.
Da quello che possiamo osservare, Googlebot raggiunge poche pagine del sito e visualizza un (finto) codice di stato 500, considerandole prive di contenuto e quindi delle Soft 404.
Contando l’alta qualità dei contenuti e la mole di risorse che certamente è stata investita per crearli, ci auguriamo che il sito quellocheconta.gov.it torni presto raggiungibile ai cittadini, posizionandosi come merita nelle SERP di Google.
Naturalmente questa analisi si basa su dati e osservazioni visti dall’esterno: qualsiasi critica costruttiva o approfondimento sul tema sono più che benvenuti e aiutano a condividere conoscenze su questi temi SEO di natura più complessa.
Aggiornamento (25 agosto)
Un’osservazione interessante ci arriva da Martino Mosna, che ha ulteriormente investigato il problema del sito:
(…) ti confermo che la rimozione del sito da Google è avvenuta a causa del soft 404. A questo punto generato da una qualche configurazione errata del CMS, difficile da diagnosticare oltre senza avere le mani dentro al cofano.
Altro dettaglio: se cancelli i cookie e poi refreshi una pagina caricata correttamente… ti ribecchi il soft 404. Ho provato diversi scenari (ci sono 3 cookie che vengono salvati), il soft 404 avviene solo se li cancelli tutti e tre.
E Googlebot di default non salva i cookie in fase di crawling… a salvare i cookie è l’hadless browser che viene utilizzato nella coda di rendering. E comunque i cookie non li tiene salvati tra una sessione di rendering e l’altra, ogni volta è come se fosse la prima.
Grazie a Martino per questo utile spunto!
