
I crawler sono programmi che cercano e indicizzano contenuti su internet, fondamentali per il funzionamento dei motori di ricerca. In questo articolo esamineremo come funzionano e cosa significano per la SEO.
Un web crawler è anche chiamato Spider perché, proprio come un ragno, si muove attraverso la rete usando collegamenti ipertestuali, raccogliendo informazioni e creando un indice. Su questo principio si è basato già il primo web crawler, che opera dal 1993 con il bel nome “World Wide Web Wanderer”. I crawler più conosciuti sono quelli dei motori di ricerca, ma ne esistono anche molti altri utilizzati per funzioni differenti.
Così funzionano i crawler
I web crawler eseguono automaticamente incarichi ripetitivi e definiti in precedenza. Si tratta quindi di bot che, a seconda di determinati codici, valutano (tra le altre cose) hashtag e keyword, indicizzando URL e contenuti. Inoltre, tramite l’interazione con tool secondari, possono confrontare i dati o seguire link e collegamenti.
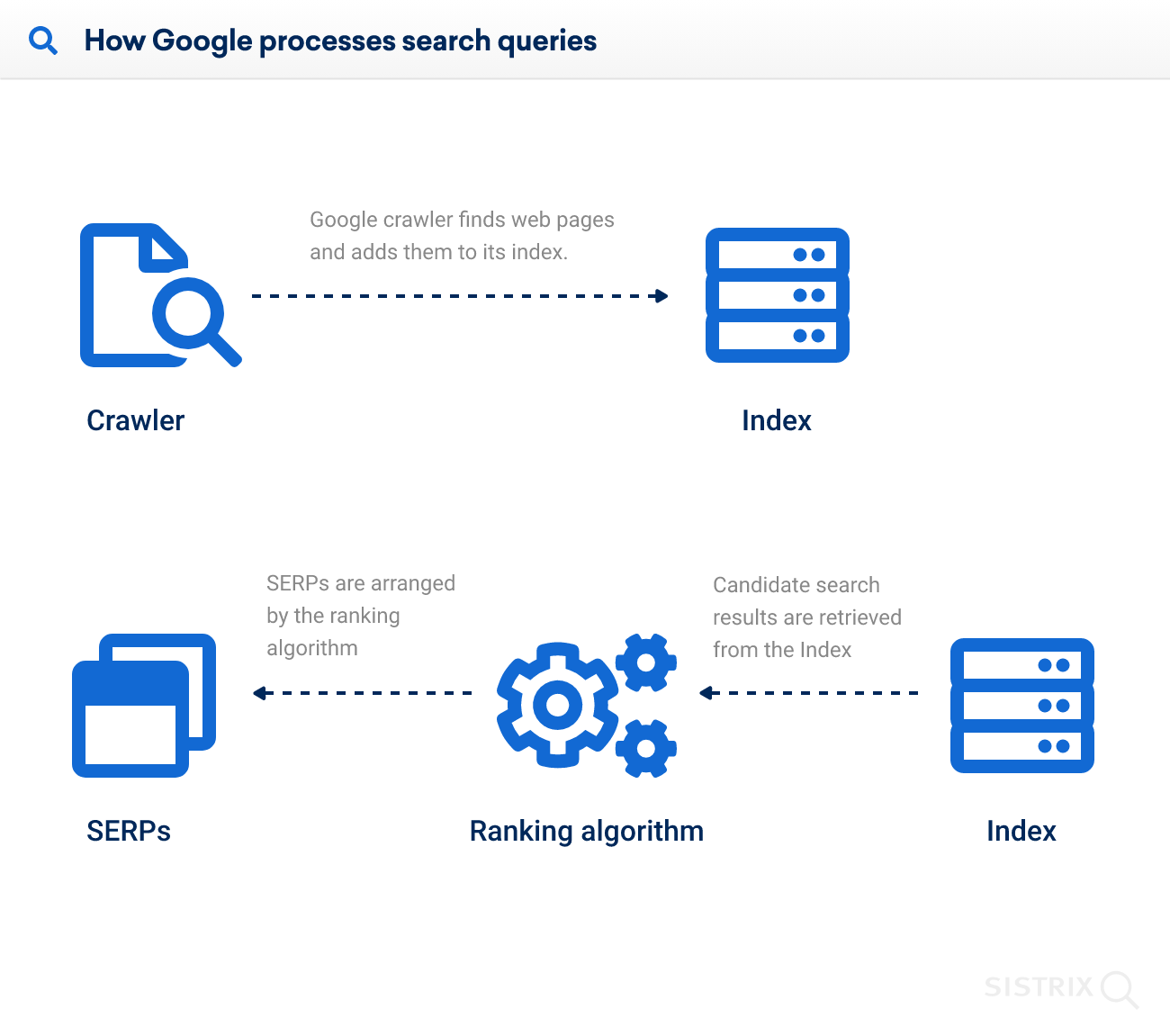
Tipi di crawler
I più conosciuti sono i crawler dei motori di ricerca, i cosiddetti Searchbot. Tra questi c’è anche Googlebot, presente in diverse versioni. Il compito principale dei Searchbot consiste nell’indicizzare i contenuti di internet e renderli disponibili agli utenti tramite i risultati di ricerca.
In altre parole, solo grazie ai crawler esistono i risultati di ricerca e solo quello che i crawler scansionano emerge come risultato.
In più i crawler sono usati per:
- Fare data mining e per esempio raccogliere indirizzi
- Effettuare analisi web
- Confrontare i dati dei prodotti per i comparatori e i portali dedicati
- Raccogliere messaggi
- Individuare i contenuti difettosi
Nota bene: i crawler non sono come gli Scraper. Mentre i web crawler sono utilizzati principalmente per estrarre, analizzare e indicizzare le informazioni, gli Scraper recuperano i dati dalle pagine web, ad esempio per rilevare determinati orari o addirittura i casi di violazioni del copyright.
Il significato dei crawler per la SEO
Esistono alcuni mezzi per influenzare la scansione dei Searchbot per il tuo sito. Ad esempio, puoi assicurarti che il crawler trovi tutte le pagine importanti o, al contrario, che non scansioni né indicizzi contenuti specifici. Entrambe le cose possono influenzare positivamente i ranking del tuo dominio.
Inoltre è possibile diminuire il consumo del Crawl Budget, cioè del numero di singoli URL che Google può e “vuole” scansionare. Si parla anche di Crawl Optimization o Crawl Budget Optimization per indicare quei metodi di ottimizzazione che puntano a creare le condizioni per avere un budget sufficiente per tutti gli URL.
Nota bene: Google stesso ha sottolineato in passato che la questione del Crawl Budget nella maggior parte dei casi è sufficiente e che i proprietari di siti web di piccole o medie dimensioni hanno di solito poco da preoccuparsi.
Consigli per la Crawl Optimisation
Per alleggerire il lavoro dei crawler e ottimizzare il Crawl Budget puoi seguire i seguenti consigli:
- Opta per un’architettura semplice e percorsi brevi per le tue pagine;
- Ottimizza i link interni;
- Usa il robots.txt per evitare che i web crawler scansionino pagine irrilevanti;
- Assicurati di fornire al crawler una sitemap XML;
- Monitora regolarmente la scansione delle tue pagine: è l’unico modo per sapere cosa potrebbe essere migliorato.
Consiglio: pur impostando correttamente il file robots.txt, può succedere che la pagina in questione venga indicizzata da Google. Per evitare sicuramente l’indicizzazione, puoi usare il comando “Noindex“.