
Per “Duplicate Content” (o “Contenuti duplicati”) s’intendono contenuti identici o molto simili tra loro, accessibili tramite più URL. I contenuti duplicati possono essere interni al sito o su domini differenti: questa differenziazione non ha rilevanza per Google.
- Perché il Duplicate Content è un problema per la SEO?
- Verificare la presenza di contenuti duplicati con SISTRIX
- Come si creano i contenuti duplicati?
- Le cause più comuni dei contenuti duplicati
- Cosa non sono i contenuti duplicati
- Cosa fa Google quando incontra dei contenuti duplicati?
- Come si possono evitare i contenuti duplicati?
- Conclusione: evita i contenuti duplicati
I contenuti duplicati pongono Google di fronte ad una decisione ardua: quale URL mostrare nei risultati di ricerca? Per rispondere, il motore di ricerca deve valutare quali segnali positivi (come i backlink o il comportamento degli utenti) debbano essere associati a quale URL. Questo può portare a fluttuazioni indesiderate nei ranking e compromettere la visibilità complessiva del sito corrispondente.
Tipicamente, il Duplicate Content si manifesta con due URL che si posizionano per la stessa keyword, ma con ranking deludenti.
Perché il Duplicate Content è un problema per la SEO?
Dal punto di vista di Google e degli altri motori di ricerca, i contenuti duplicati non solo non offrono alcun valore aggiunto, ma rappresentano anche un problema. I crawler preferiscono indicizzare e mostrare contenuti originali e utili: il Duplicate Content rende questo compito più difficile, poiché i motori di ricerca devono impiegare più risorse per identificare le pagine pertinenti. Inoltre, creano un’inutile competizione interna per i ranking, che dovrebbe essere assolutamente evitata.
Se la stessa informazione viene offerta su più URL diversi, può accadere che:
- l’URL sbagliato si posizioni nei risultati di ricerca
- i segnali di ranking si distribuiscano su più pagine
- il crawl budget venga consumato inutilmente, ritardando o impedendo l’indicizzazione di pagine importanti
Il Duplicate Content non porta automaticamente a una penalizzazione, e Google ha più volte sottolineato che, in molti casi, l’algoritmo è in grado di selezionare autonomamente la versione migliore. Tuttavia, un uso manipolativo degli stessi (come la copia massiccia di contenuti di altri siti) può comportare perdite di ranking o persino la rimozione dall’indice.
Verificare la presenza di contenuti duplicati con SISTRIX
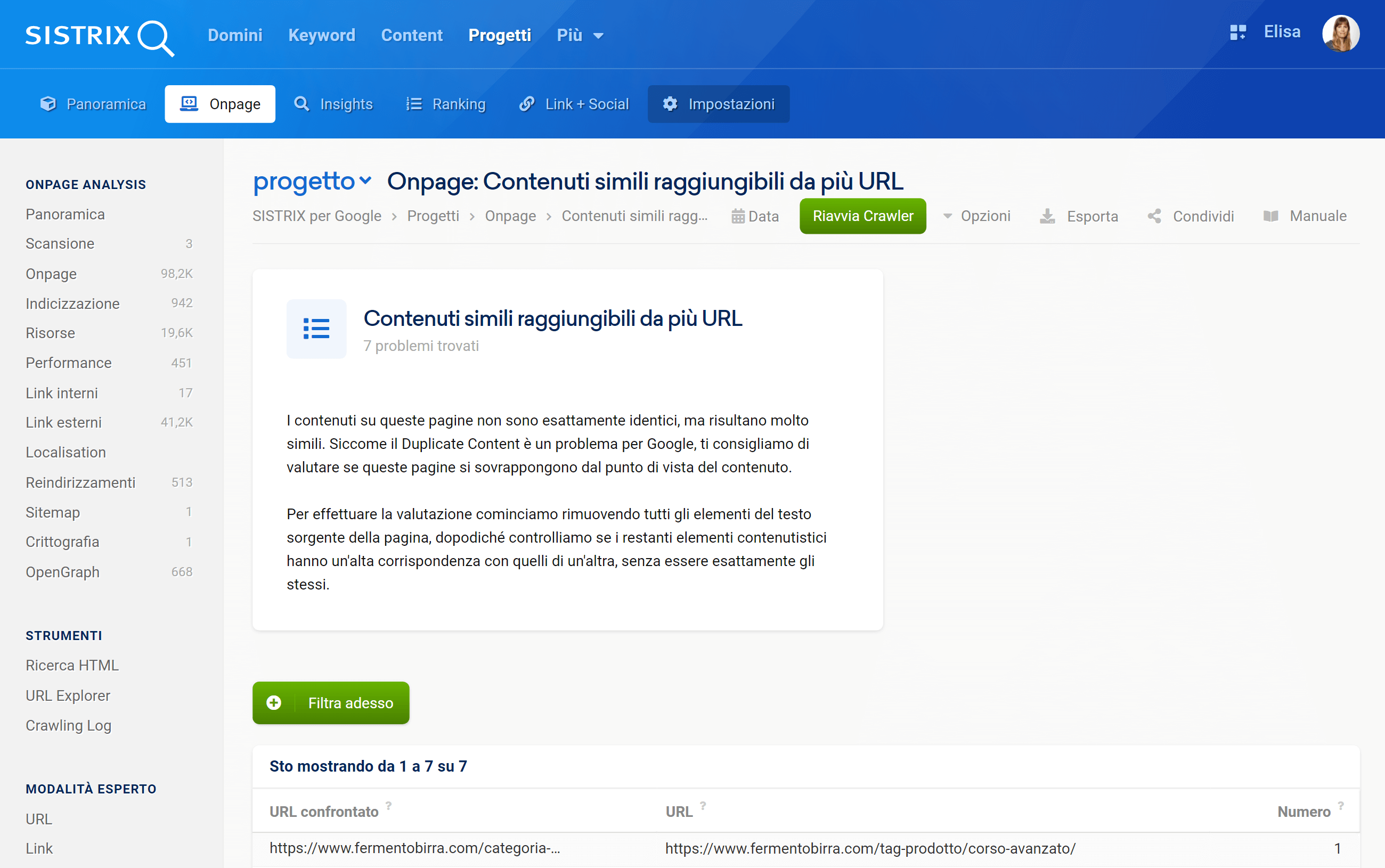
Il Duplicate Content è uno dei problemi tecnici più comuni dei siti web e, purtroppo, non è sempre facile da individuare. I contenuti che sono (quasi) identici e accessibili tramite URL differenti possono rendere l’indicizzazione più difficile e far perdere posizionamenti. Le pagine più colpite sono quelle con molte varianti di URL, create ad esempio a causa di filtri, ordinamenti o parametri di tracciamento.
Con un progetto Onpage di SISTRIX potrai analizzare automaticamente il tuo sito e rilevare in modo affidabile i contenuti duplicati. Tutti gli URL interessati vengono elencati in modo chiaro, insieme ai suggerimenti sul perché si tratta di Duplicate Content e su cosa si possa fare concretamente per risolvere il problema. Inoltre, nelle impostazioni del progetto puoi definire in modo mirato quali parametri URL devono essere ignorati o ordinati per evitare i duplicati indesiderati.
I risultati possono essere filtrati per priorità, in modo da permetterti d’iniziare con le problematiche più importanti. Grazie a questa funzione il Duplicate Content non diventa solo facilmente individuabile, ma anche risolvibile!
Per saperne di più sui dati dell’Indice di Visibilità per il tuo sito testa subito SISTRIX gratuitamente: avrai accesso a tutti i dati mostrati in questo Indexwatch e tante altre funzionalità.
Come si creano i contenuti duplicati?
La formazione di contenuti duplicati avviene per lo più in modo involontario. Il rischio è elevato soprattutto nei siti molto grandi, che hanno quindi molti prodotti, contenuti editoriali o filtri tecnici. Le cause tipiche sono:
1. Contenuti duplicati tecnici all’interno di un dominio
Accade spesso che la stessa pagina sia accessibile tramite URL diversi a causa, ad esempio, di:
- Parametri URL (ad esempio ?ref=xyz)
- Funzioni di ordinamento e filtri negli e-commerce
- ID di sessione
- Diverse forme di scrittura o strutture di percorso (ad esempio /prodotto e /prodotto/)
2. Contenuti duplicati dovuti a domini diversi
Un sito è spesso accessibile da più indirizzi, ad esempio con e senza “www”, con domini nazionali diversi o tramite URL alternativi. Se non sono stati impostati dei Redirect, Google li riconosce come pagine separate con un contenuto identico.
3. Contenuti su più siti web
Quando i testi vengono pubblicati o distribuiti in syndication su più domini senza una chiara indicazione della fonte originale, si creano anche in questo caso dei contenuti duplicati. Questo fenomeno è particolarmente problematico quando tutte le versioni vengono indicizzate nello stesso mercato linguistico e di destinazione (ad esempio google.it).
Le cause più comuni dei contenuti duplicati
| Causa | Esempio |
|---|---|
| Parametri URL | ?ref=123, &sort=preis, ?utm_source=xyz |
| Più domini / protocolli | http:// vs. https://, www. vs. niente www. |
| Canonical Tag errato o mancante | Non inserito o che punta a se stesso |
| Versioni stampabili o mobile indicizzabili | /pagina/stampa, /m/pagina senza noindex |
| Trailing slash non uniforme | /pagina vs. /pagina/ |
| Maiuscole e minuscole negli URL | /Prodotto ≠ /prodotto |
| Contenuti su più domini | Testi identici su sito.it e sito.net |
| Mancanza dell'indicazione hreflang per le versioni linguistiche | example.com/it e example.it nello stesso mercato |
| ID di sessione o parametri di tracciamento | ?sessionid=abc123, ?track=456 |
| Percorsi duplicati a causa di categorie o tag | /tag/seo, /categoria/seo con lo stesso contenuto |
Cosa non sono i contenuti duplicati
Non tutte le sovrapposizioni di contenuto sono problematiche. Google riconosce e tollera determinate forme di duplicazione, tra cui:
- Citazioni: le citazioni contrassegnate correttamente e con l’indicazione della fonte non rappresentano un problema;
- Traduzioni: i contenuti in lingue diverse non sono considerati duplicati, a condizione che siano differenziati linguisticamente in modo corretto e contrassegnati tramite tag hreflang;
- Impaginazione: se l’implementazione tecnica è pulita, anche l’impaginazione delle pagine (ad esempio nei blog o nelle pagine di categoria) non è problematica e viene riconosciuta da Google senza difficoltà.
L’importante è che Google possa riconoscere se si tratta di contenuto originale o copiato, e quale URL dev’essere preferito.
Cosa fa Google quando incontra dei contenuti duplicati?
Oggi Google è molto bravo a riconoscere i contenuti duplicati e a selezionare automaticamente la versione migliore dal punto di vista dell’utente, che si tratti di una pagina all’interno di un dominio o di una versione su un altro dominio. Per farlo, Google considera i punti seguenti:
- La struttura tecnica della pagina
- I Canonical-Tag esistenti
- I segnali esterni come i backlink
- Il comportamento degli utenti
Nella maggior parte dei casi, Google mostra una sola versione del contenuto nelle pagine dei risultati di ricerca. Tuttavia, possono verificarsi fluttuazioni indesiderate nei ranking quando i segnali non possono essere associati in modo univoco, specialmente se esistono molte versioni e non viene comunicata una chiara preferenza.
Come si possono evitare i contenuti duplicati?
Per evitare il Duplicate Content Google raccomanda di fornire segnali chiari. Tra questi, in particolare:
Canonical-Tag
Tramite il tag canonical, si indica l’URL preferito nell’<head> di una pagina:
<link rel=“canonical“ href=“https://www.esempio.it/pagina-preferita“ />In questo modo, si comunica a Google quale versione dev’essere indicizzata, cosa particolarmente importante per le pagine di prodotto, i filtri e i contenuti con varianti.
Redirect 301
Tutte le URL alternative, ad esempio con e senza “www.”, “http” e “https”, devono essere reindirizzate in modo permanente a un URL principale tramite un redirect 301. In questo modo, è possibile consolidare anche i contenuti duplicati su più domini.
Struttura degli URL e dei link interni “pulita”
I link interni devono sempre puntare alla versione canonica di una pagina. Le incoerenze interne sono una causa comune di Duplicate Content.
Gestione dei parametri su Google Search Console
Per i siti con molti parametri URL, ad esempio gli e-commerce con funzioni di ordinamento, si raccomanda la gestione mirata di questi parametri su Google Search Console, dove è possibile comunicare a Google quali parametri modificano i contenuti e quali no.
Conclusione: evita i contenuti duplicati
Nella maggior parte dei casi i contenuti duplicati possono essere evitati con un’implementazione tecnica pulita e una struttura chiara. Sebbene Google sia oggi decisamente più bravo a gestire il problema, dal punto di vista SEO ha senso mantenere il controllo in autonomia: ogni URL dovrebbe contenere un contenuto unico, che non si trova su altre pagine.
Chi struttura i propri contenuti in modo chiaro, comunicando gli URL “preferiti” e riducendo in modo coerente i duplicati, ne trae vantaggio a lungo termine con ranking più stabili, una migliore visibilità e un crawl budget più efficiente.
Prova SISTRIX gratis
- Account di prova gratuito per 7 giorni
- Nessun obbligo, né disdetta necessaria
- Onboarding personalizzato con esperti