
Un URL (Uniform Resource Locator) è l’indirizzo univoco di una risorsa su internet. Esso permette di richiamare in modo mirato pagine web, immagini o altri contenuti. Un URL ben strutturato non solo migliora l’esperienza dell’utente, ma svolge anche un ruolo importante nell’ottimizzazione per i motori di ricerca (SEO).
- Struttura e componenti di un URL
- Che importanza hanno gli URL per la SEO?
- Leggibilità e User-Friendliness
- Evitare i contenuti duplicati
- Caratteri speciali e convenzioni di scrittura negli URL
- HTTP vs. HTTPS: sicurezza e SEO
- Reindirizzamenti di URL: come reindirizzare correttamente con Redirect 301 e 302
- Quando sono necessari i reindirizzamenti?
- Differenza tra Redirect 301 e 302
- Best Practice per URL "SEO-Friendly"
- Analisi degli URL con SISTRIX
- Gli URL parlanti sono utili, ma non sono un fattore di ranking
- FAQ: domande frequenti sugli URL
- Come devo gestire gli spazi negli URL?
- Qual è la lunghezza massima consentita per un URL?
- Ha senso accorciare o rinominare gli URL in un secondo momento?
- L'URL dovrebbe includere la categoria?
- Cos'è meglio: trattino basso o trattino normale?
- La distinzione tra maiuscole e minuscole è rilevante negli URL?
- Cosa succede se due URL mostrano lo stesso contenuto?
- Come posso personalizzare il formato URL su WordPress?
Struttura e componenti di un URL
Un URL è generalmente composto da diverse componenti. Per comprenderne la struttura e le sue singole parti, analizzeremo il seguente URL d’esempio suddividendolo nei suoi elementi costitutivi:
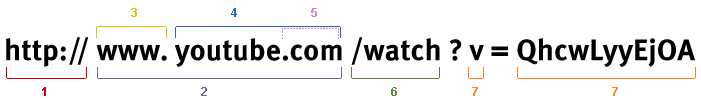
- Il protocollo utilizzato: in questo caso HTTP (Hypertext Transfer Protocol). Altri protocolli sono ad esempio HTTPS, FTP, etc.
- L’host o l’hostname: www.youtube.com
- Il sottodominio: www. (ormai non più assolutamente necessario)
- Il dominio: youtube.com
- Il Top-Level-Domain (TLD – l’estensione dell’indirizzo internet): .com
- Il path: /watch. Un percorso indica solitamente un file o una cartella (directory) su un server web (ad esempio “/cartella/file.html”)
- Parametri e valori: v (parametro), QhcwLyyEjOA (valore del parametro). I parametri sono preceduti dal simbolo “?” all’interno di un URL. Il nome del parametro nel nostro caso è “v” e il suo valore “QhcwLyyEjOA” (il nome del parametro e il suo valore si presentano sempre secondo lo stesso schema: nome parametro=valore parametro).
Che importanza hanno gli URL per la SEO?
Leggibilità e User-Friendliness
URL chiari e comprensibili aiutano gli utenti e i motori di ricerca a comprendere rapidamente il contenuto di una pagina. URL parlanti come esempio.com/consigli-seo sono molto più significativi di sequenze criptiche di caratteri come esempio.com/p=12345. Una struttura di questo tipo aumenta la fiducia degli utenti e può incrementare il Click-Through Rate (CTR). Inoltre, gli URL parlanti possono essere analizzati e filtrati meglio in Tool SEO come Google Search Console, Google Analytics o SISTRIX.
Evitare i contenuti duplicati
Gli URL dinamici con molti parametri possono far sì che contenuti identici siano accessibili tramite indirizzi diversi, portando al Duplicate Content (o contenuti duplicati), influenzando negativamente il posizionamento del sito. L’uso di tag canonical o la pulizia della struttura degli URL aiuta a evitare questo problema.
Ecco la traduzione del testo, focalizzata sulle linee guida per caratteri, sicurezza e SEO:
Caratteri speciali e convenzioni di scrittura negli URL
Negli URL è necessario evitare determinati caratteri (come spazi o vocali con accenti), poiché possono causare problemi di visualizzazione. Al contrario, gli spazi dovrebbero essere sostituiti con i trattini e le vocali con l’accento scritte preferibilmente senza (ad esempio, caffé.it diventa caffe.it). Inoltre, è consigliabile utilizzare sempre lettere minuscole ed evitare i caratteri speciali.
HTTP vs. HTTPS: sicurezza e SEO
Google predilige i siti sicuri con protocollo HTTPS, in quanto crittografano la trasmissione dei dati, aumentando così la sicurezza degli utenti: essi godono spesso di un miglior posizionamento e rafforzano la fiducia dei visitatori.
Ecco la traduzione del testo, focalizzata sul concetto di reindirizzamento URL e sulla distinzione tra i codici 301 e 302:
Reindirizzamenti di URL: come reindirizzare correttamente con Redirect 301 e 302
Quando sono necessari i reindirizzamenti?
I reindirizzamenti dovrebbero essere configurati in caso di modifiche alla struttura degli URL, spostamenti di contenuti o consolidamenti, al fine d’indirizzare correttamente utenti e motori di ricerca.
Differenza tra Redirect 301 e 302
- Redirect 301: reindirizzamento permanente che trasferisce i segnali di ranking
- Redirect 302: reindirizzamento temporaneo che non sempre offre vantaggi SEO
Per le modifiche permanenti è necessario utilizzare sempre un reindirizzamento 301 così da non perdere posizionamenti.
Best Practice per URL “SEO-Friendly”
- Evitare parametri superflui: mantieni la struttura degli URL pulita ed evita parametri inutili
- Breve e concisa: evita parole o numeri non necessari
- Utilizzare termini parlanti: usa parole chiare e descrittive
- Usare le minuscole: gli URL dovrebbero essere scritti in modo coerente in minuscolo
- Trattini al posto di underscore: separa le parole con i trattini (-), ma evita i trattini bassi (_)
Ecco la traduzione del testo, focalizzata sull’utilizzo di SISTRIX per l’analisi delle URL in ottica SEO:
Analisi degli URL con SISTRIX
L’analisi di singoli URL è una componente fondamentale dell’ottimizzazione per i motori di ricerca. Con SISTRIX puoi ricevere informazioni dettagliate sulla visibilità e sul posizionamento delle singole pagine del tuo sito: in questo modo saprai dove implementare ottimizzazioni mirate e migliorare le performance dei singoli contenuti.
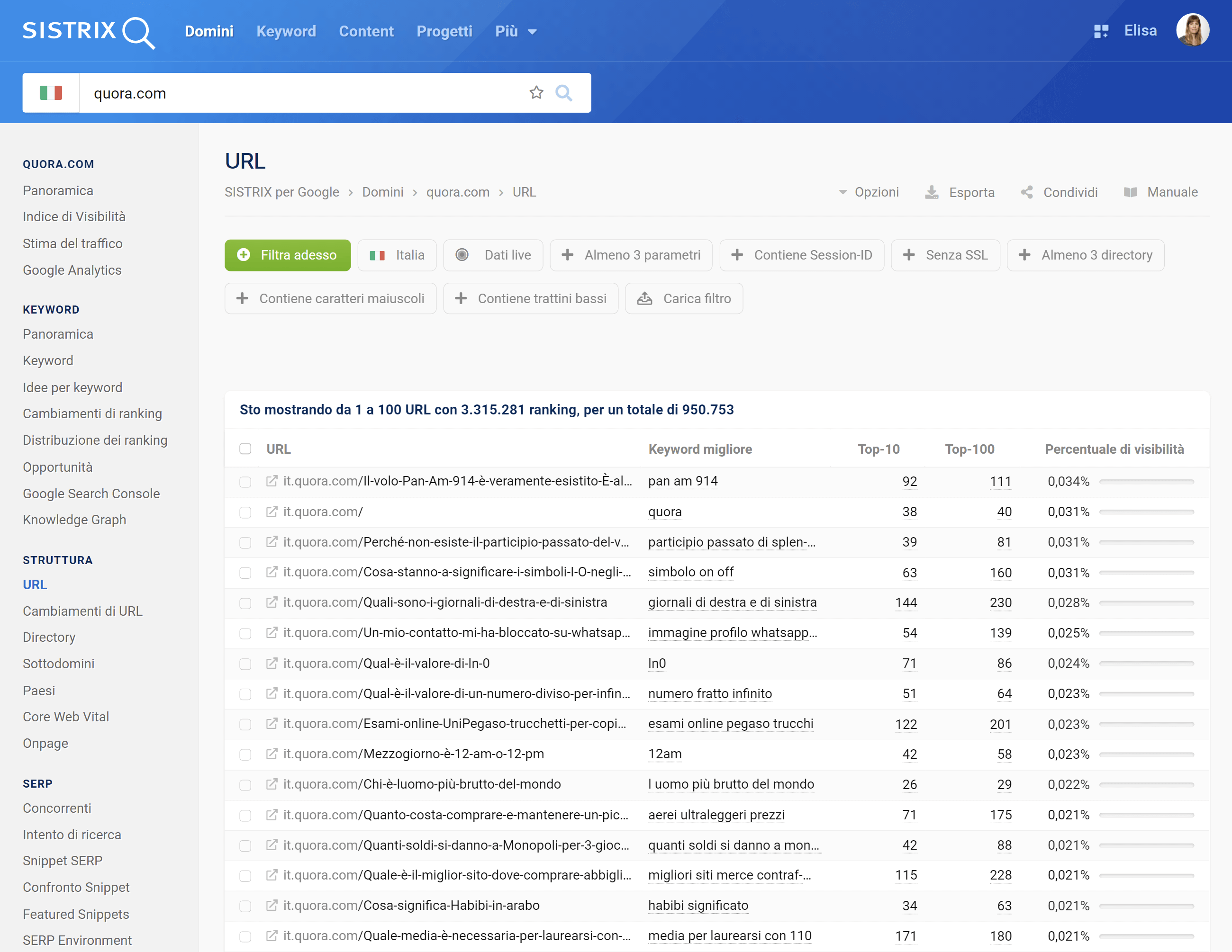
Nella sezione “URL”, otterrai una panoramica di tutte le pagine del tuo dominio che appaiono nei risultati di ricerca di Google tra i primi 10 o i primi 100 risultati, inclusa la keyword migliore per quell’URL specifico (ossia quella che genera il maggior numero di click organici). Inoltre, potrai vedere quanto ogni URL contribuisce alla visibilità complessiva del tuo dominio.
Se desideri analizzare in modo mirato una pagina specifica, è sufficiente inserire l’URL nella barra di ricerca di SISTRIX: riceverai dati che includono l’Indice di Visibilità, i link in entrata e in uscita, e le keyword per le quali la pagina si posiziona.
Con pratici filtri (ad esempio, per profondità della directory, SSL o parametri URL) puoi affinare ulteriormente l’analisi così da identificare problemi tecnici e ottimizzare la struttura degli URL.
Con SISTRIX puoi analizzare in modo mirato quali URL del tuo sito hanno particolare successo, e dove esiste invece ancora un potenziale di ottimizzazione. Scopri subito come puoi migliorare la struttura delle tue pagine e aumentare in modo duraturo la visibilità nella ricerca di Google grazie a insight basati sui dati. Prova subito l’intero tool senza alcun costo nascosto, né disdetta necessaria per sette giorni: testa subito SISTRIX gratuitamente!
Gli URL parlanti sono utili, ma non sono un fattore di ranking
Gli URL sono una componente fondamentale di qualsiasi sito, ma non hanno un’influenza diretta sulla performance SEO. Sono infatti solo un indirizzo univoco e leggibile dai motori di ricerca. Una struttura di URL ben studiata e pulita migliora però l’esperienza dell’utente e aiuta nell’analisi dei dati.
Prova SISTRIX gratis
- Account di prova gratuito per 7 giorni
- Nessun obbligo, né disdetta necessaria
- Onboarding personalizzato con esperti