
La Inverse Document Frequency (in italiano “Frequenza inversa del documento” o IDF) indica quante volte un certo termine ricorre in un insieme definito di documenti. In questo modo è possibile calcolare l’unicità di una parola all’interno di questo gruppo di documenti.
La frequenza inversa del documento deriva dalle scienze dell’informazione e aiuta a verificare se determinate parole sono presenti in molti o pochi documenti di una raccolta precedentemente definita.
Scopri subito come sfruttare SISTRIX per il tuo business online! Sette giorni per provare l’intero tool senza alcun costo nascosto, né disdetta necessaria: testa subito SISTRIX gratuitamente.
Da dove deriva la Inverse Document Frequency?
Le basi del valore IDF sono state gettate nel 1972 dall’informatica britannica Karen Spärck Jones. Nel suo articolo “A statistical interpretation of term specificity and its application in retrieval” (“Un’interpretazione statistica della specificità dei termini e la sua applicazione nel reperimento”), è stata la prima nel suo campo a definire come si può calcolare la specificità di un termine /di una keyword.
L’idea che si nasconde dietro a questo metodo è elegante e facile da capire: una parola di una query di ricerca che ricorre in molti documenti non è un discriminante adeguato e per questo motivo dovrebbe avere meno peso rispetto ad una parola che ricorre in pochissimi documenti.
In che modo l’IDF mi aiuta nelle analisi?
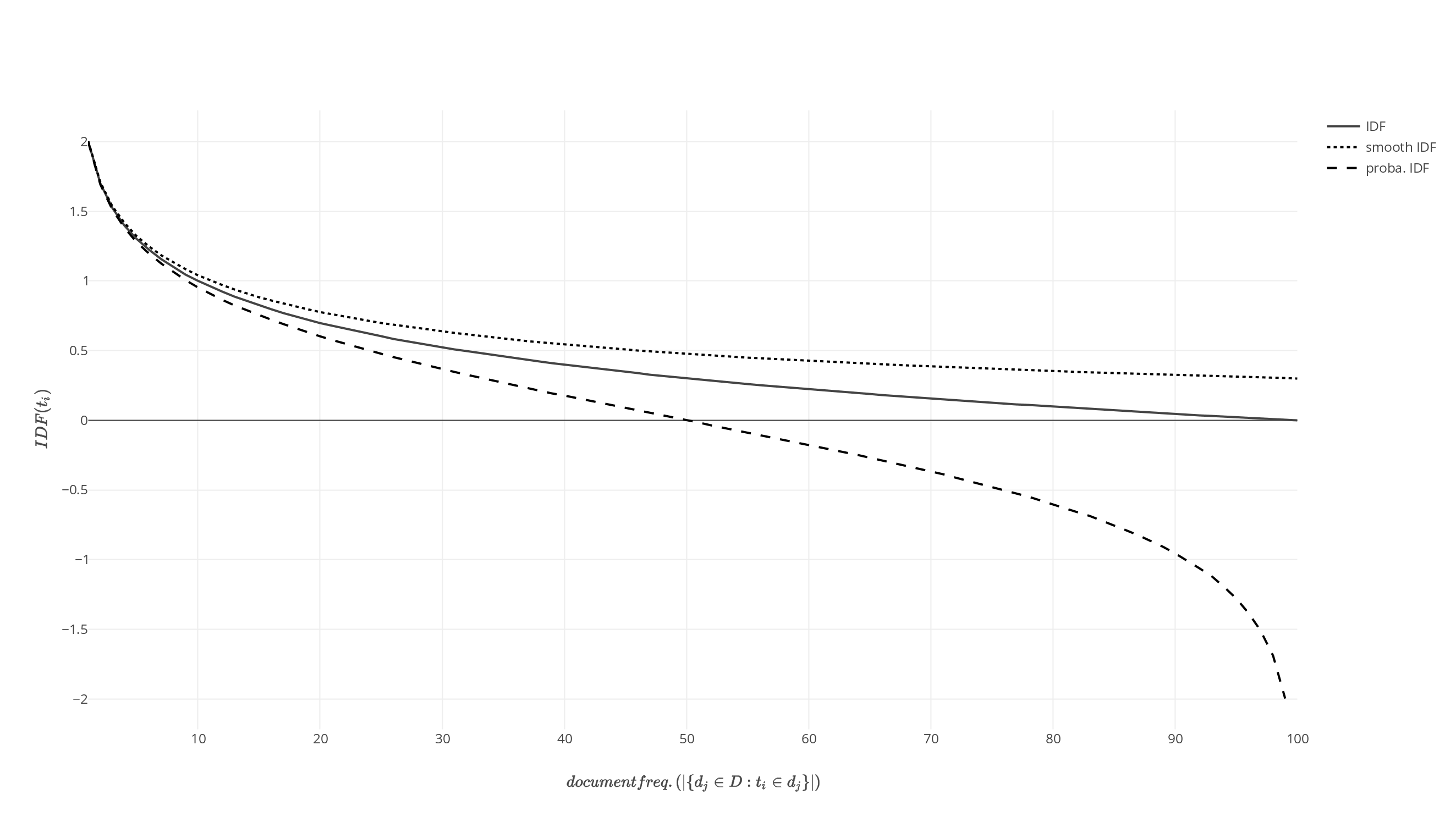
Dal punto di vista matematico l’Inverse Document Frequency per una parola specifica (IDFt) divide il numero di documenti della raccolta di documenti (ND) per il numero di documenti della stessa raccolta che contengono questa parola specifica (ƒt):
Questo significa che il valore IDF per una parola diminuisce quanto più documenti della raccolta contengono questa parola!
Le “Stop Words” (“allora”, “le”, “hanno”, ecc.) , ad esempio, possono essere calcolate molto bene, poiché sono presenti in una percentuale molto elevata di documenti.
Esempio 1 di IDF
Un esempio potrebbe essere una raccolta di 100 documenti, dove in ogni documento compare la parola “il”:
La parola “il” non ha un’unicità in questa raccolta di documenti.
Esempio 2 di IDF
Nella stessa raccolta di documenti la parola “lo” compare 50 volte:
A causa del logaritmo, un’occorrenza nel 50% dei casi possibili non è più il 50% dell’unicità totale (che sarebbe il caso con il valore 1), ma un valore di 0,3.
Esempio 3 di IDF
Infine, supponiamo che la parola “xilofono” sia presente esattamente in un documento del corpus dei documenti di cui sopra:
L’unicità assoluta di una parola all’interno di una raccolta di documenti ha un valore massimo di 2 per la considerazione di cui sopra.
Conclusione sulla Inverse Document Frequency
L’IDF può essere utilizzato molto bene per ponderare i seguenti concetti: quali parole ricorrono frequentemente in un singolo documento, ma sono relativamente uniche in tutti i documenti che esaminiamo? Oppure quali parole sono presenti in tutti i documenti e sono quindi probabilmente meno interessanti?
Non importa se stiamo parlando della pura Keyword Density (frequenza dei termini) o di un valore ponderato (Within Document Frequency o WDF).
IDF come polo opposto alla frequenza dei termini e alla frequenza all’interno del documento
Nelle due analisi di ponderazione TF-IDF e WDF-IDF, il valore IDF ha la funzione di attribuire un punteggio inferiore alle parole che ricorrono in tutti i documenti.
Più frequentemente una parola ricorre in un documento, più alto è il valore TF/WDF, mentre più frequentemente una parola ricorre in tutti i documenti, più basso è l’IDF.
Le Stop Words che ricorrono in (quasi) tutti i documenti perdono quindi importanza, indipendentemente dalla frequenza con cui ricorrono in un singolo documento, in quanto il loro valore IDF è prossimo a 0.
Prova SISTRIX gratis
- Account di prova gratuito per 7 giorni
- Nessun obbligo, né disdetta necessaria
- Onboarding personalizzato con esperti