
La maggior parte delle analisi e delle funzioni del SISTRIX si basano già sui dati SERP del database esteso. Tali dati verranno ora utilizzati anche come impostazione predefinita per la cronologia delle keyword e degli URL di ranking.
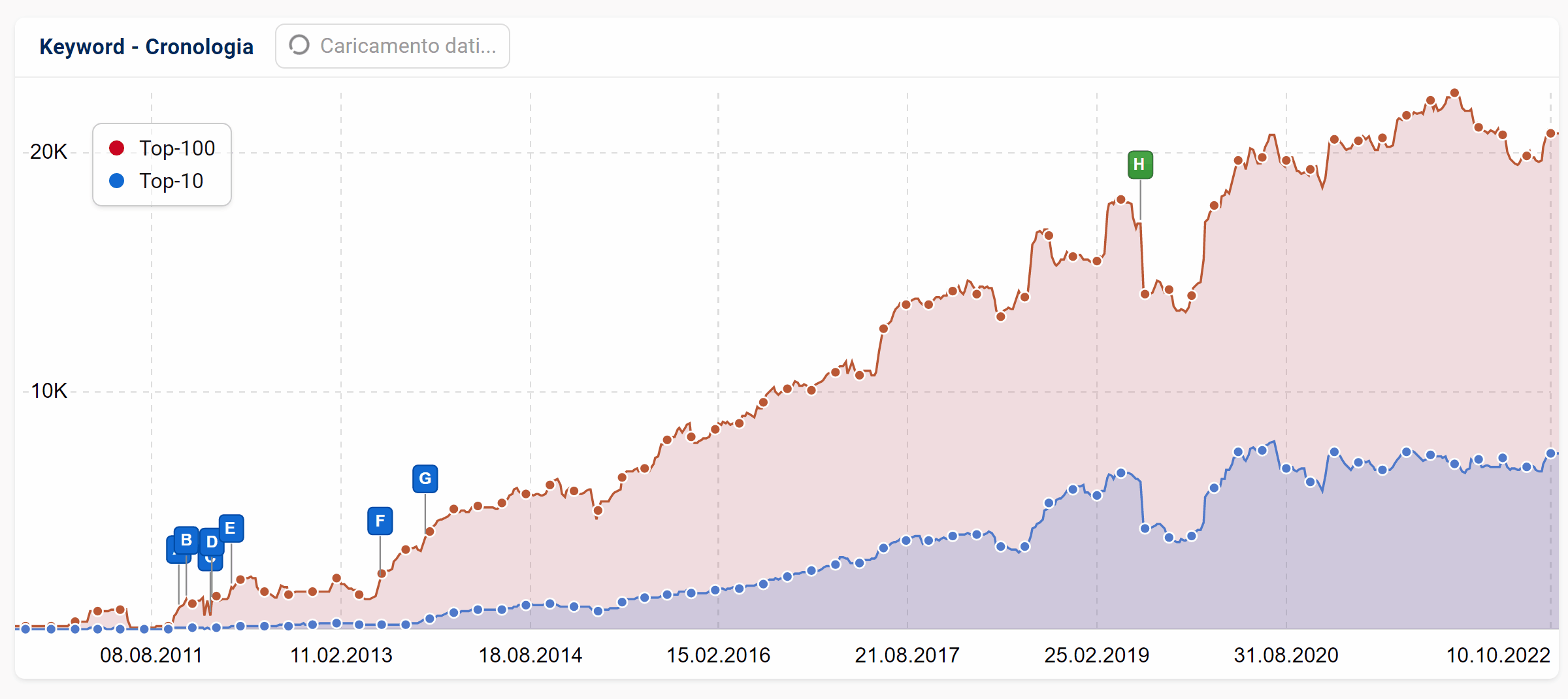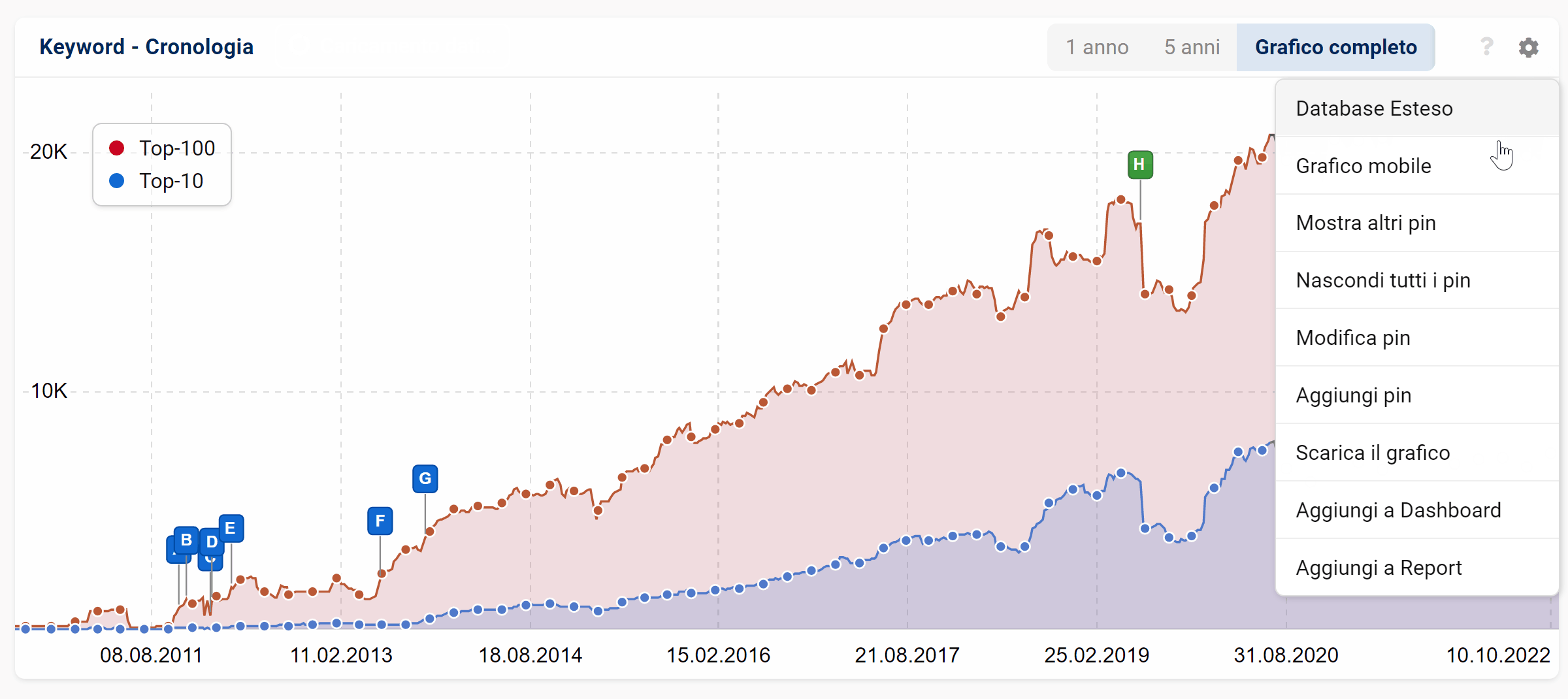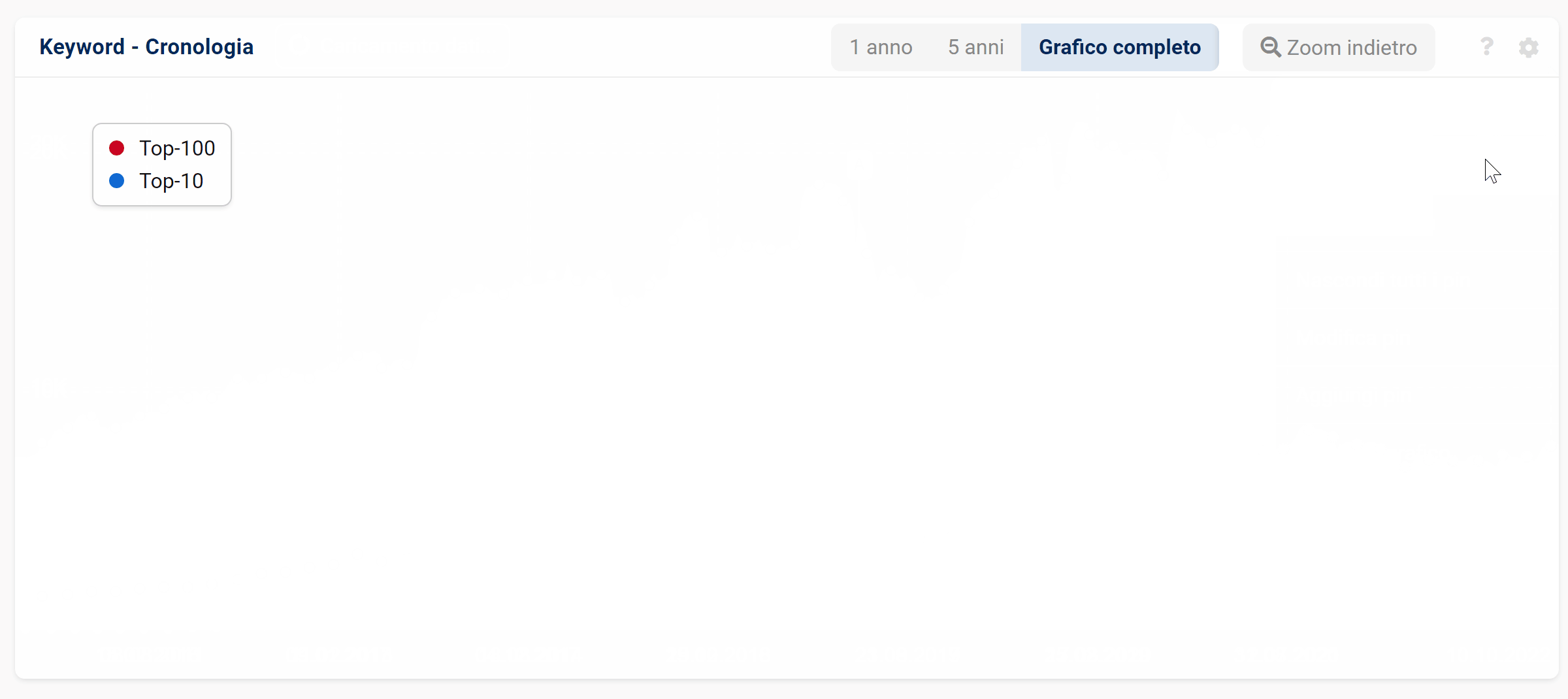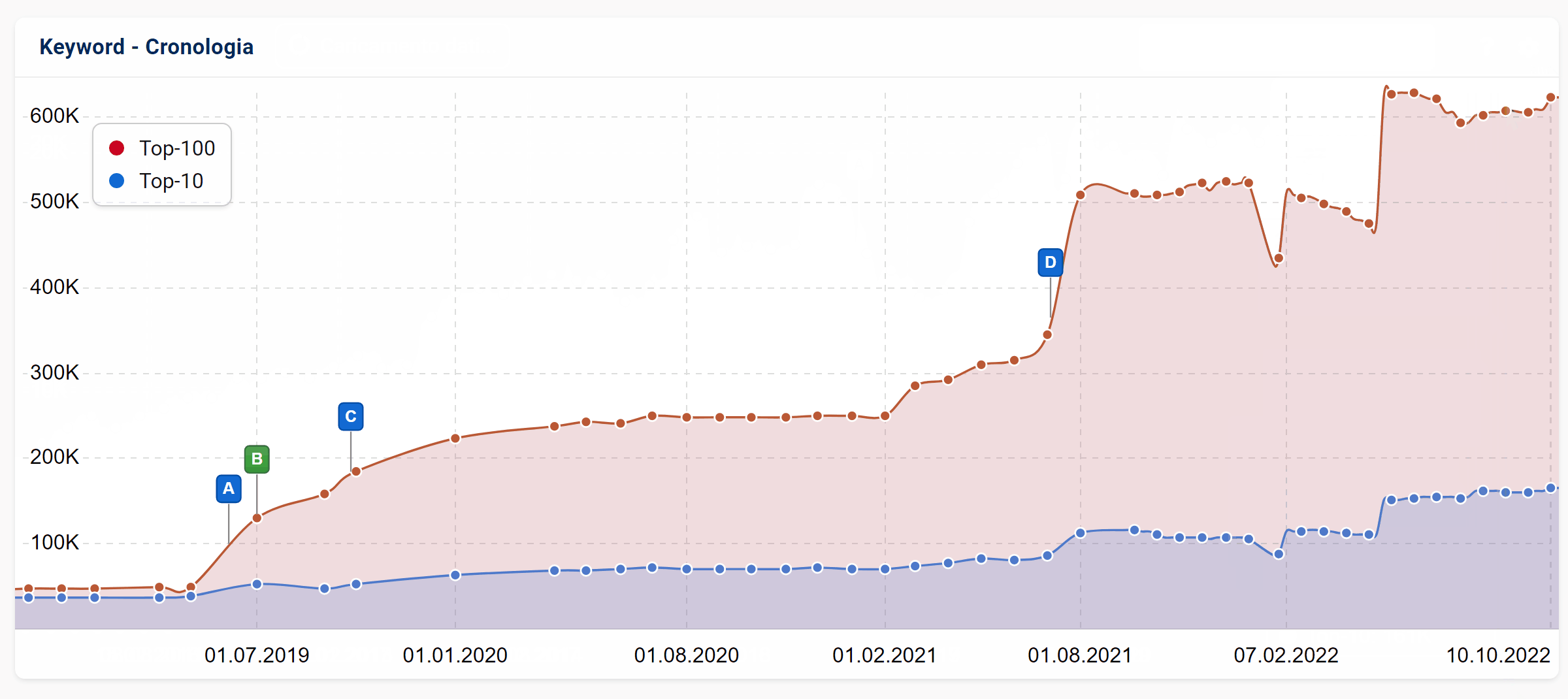
Il numero di ranking di una pagina in Top-10 e Top-100 di Google, nonché il numero di URL differenti che si posizionano, sono informazioni interessanti per un SEO, soprattutto per le analisi cronologiche.
Mentre in precedenza la visualizzazione di questi dati riguardava un milione di keyword, la nuova impostazione predefinita si basa ora sui dati avanzati.
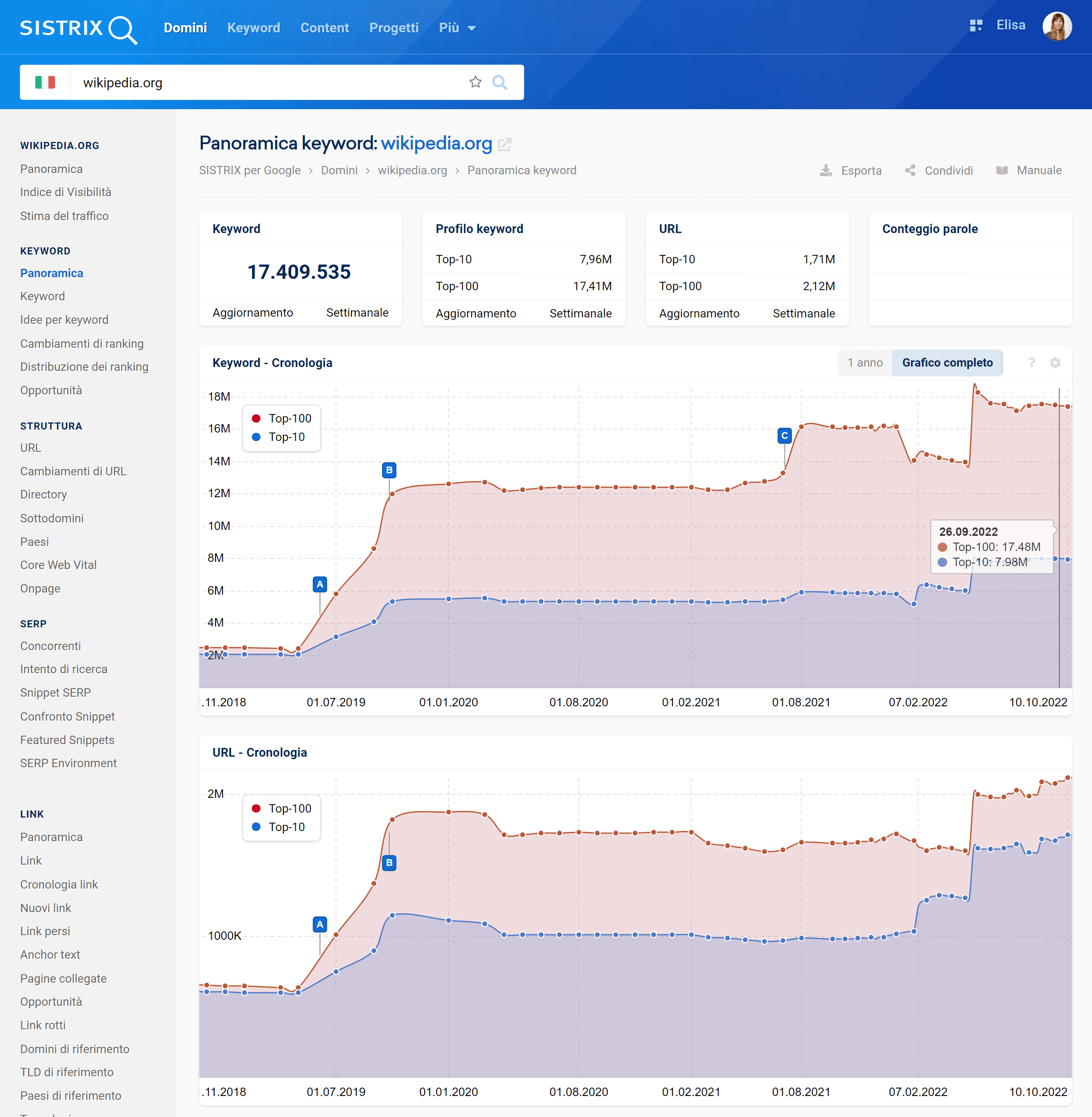
A tal fine, conserviamo un’istantanea settimanale dei dati di ranking per ciascuno degli ultimi dodici mesi, mentre, per i periodi precedenti, li riduciamo ad un punto-dato per mese.
Come sempre con SISTRIX, questi dati possono essere visualizzati e analizzati retrospettivamente nel tempo non solo per interi domini, ma anche per sottodomini, directory o singoli URL.
Dati standard per smartphone e desktop ancora disponibili
Naturalmente, è ancora possibile utilizzare gli sviluppi basati sui dati standard (un milione di keyword) per le SERP smartphone e desktop. Per passare da una fonte di dati all’altra ti basterà usare le opzioni del grafico corrispondente in qualsiasi momento desideri.
Quale database si adatta meglio alle mie analisi?
Come spesso accade nell’ottimizzazione dei motori di ricerca, purtroppo non esiste una risposta univoca a questa domanda. Di seguito quindi riportiamo i principali vantaggi e svantaggi dei due tipi di database.
I dati aggiornati quotidianamente hanno il vantaggio di essere molto attuali. I cambiamenti sono visibili immediatamente e risultano utili per analizzare gli aggiornamenti degli algoritmi, le migrazioni e altri cambiamenti immediati. Sono anche statisticamente comparabili nel tempo, in quanto ciascun Paese e dispositivo possiede sempre un milione di keyword.
Lo svantaggio dei dati aggiornati quotidianamente è che ci sono “solo” (per l’appunto) un milione di keyword. Soprattutto per i domini di nicchia più piccoli, questo set di parole chiave non copre sempre tutti i casi speciali, le ortografie e i termini longtail. Lo stesso vale se si analizzano singole directory o addirittura URL del dominio: sulla base di un milione di keyword, il database può diventare un po’ troppo scarno.
Questo è il vantaggio del database esteso, che ora viene utilizzato come standard: ad esempio, in Italia le analisi non si basano più su un milione di keyword, bensì su oltre 51 milioni. Un elenco aggiornato delle dimensioni del database per tutti i Paesi è disponibile in questa pagina.
Uno svantaggio dei dati estesi è la frequenza di aggiornamento: sebbene tutte le keyword “importanti” vengano aggiornate quotidianamente, quelle longtail raramente ricercate lo sono solo mensilmente. Pertanto, i cambiamenti nel corso dei dati estesi possono diventare evidenti solo dopo alcune settimane.
Infine, amplieremo regolarmente i database estesi dei Paesi supportati: questo comporterà un aumento nei grafici non combaciante con lo status quo reale. Tali espansioni verranno quindi comunicate e segnalate tramite pin.